ElasticSearch 설치 및 검색하기
ChatGPT 요약
데이터베이스에 많은 데이터가 있을 때(1억 이상의 데이터), 사용자가 검색 API를 호출하면 데이터를 검색하는 속도가 크게 느려질 수 있습니다.
특정 ID로 검색하는 경우라면 인덱스를 적절히 적용하면 성능 문제는 크게 없겠지만, 검색 기능과 같은 경우에는 이야기가 달라집니다.
예를 들어, "도서" 구매 사이트를 가정해 보겠습니다. 세상에는 매우 많은 책들이 존재하며, 우리가 어떤 책을 검색하려고 한다면 책 이름으로 검색하는 경우가 많을 것입니다.
그런데, 만약 사용자가 책 이름을 정확히 기억하지 못하고 일부만 기억하는 경우에는 어떻게 될까요? 검색 시, 일반적인 데이터베이스에서는 LIKE 'xxx%'와 같은 기법으로 데이터를 조회할 수 있습니다. 하지만 LIKE '%xxx%'와 같은 방식으로 조회하면 결국 인덱스를 활용하지 못하고 **풀 스캔(full scan)**이 발생해 데이터베이스에 큰 부하가 걸리게 됩니다.
그렇다면, LIKE 'xxx%' 방식으로만 검색을 허용하자고 한다면 어떨까요? 이는 사용자에게 상당한 불편함을 초래할 것입니다.
예를 들어, 사용자가 찾고자 하는 책의 이름이 **"달빛 조각사"**라고 가정해 봅시다. 만약 사용자가 이름을 정확히 기억하지 못하고 "조각사"라고만 검색한다면, LIKE 'xxx%' 방식으로는 당연히 검색 결과에 해당 책이 나타나지 않을 것입니다.
이 문제를 해결하기 위해 여러 방법이 존재합니다. PostgreSQL에서는 Full Text Search 기능을 제공하여 검색 성능을 개선할 수 있습니다. 하지만 데이터가 많아질수록 Full Text Search 역시 성능 문제가 발생할 수 있습니다. 이때 해결책으로 활용할 수 있는 도구가 바로 Elasticsearch입니다.
Elasticsearch는 검색 기능을 위해 설계된 강력한 도구로, 대규모 데이터를 효율적으로 검색할 수 있어 많은 서비스에서 검색 기반 기능을 구현할 때 사용되고 있습니다.
ElasticSearch 설치
https://www.elastic.co/kr/downloads/elasticsearch
Elasticsearch를 사용하는 방법은 비교적 간단합니다. Elasticsearch의 공식 홈페이지에 접속하여 설치 가이드를 참고하면 됩니다.
저는 Docker 를 이용해서 설치해보겠습니다.
(https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html)
# 네트워크 생성
docker network create elastic
# Elastic Search pull
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.16.0
# Elastic Search 설치 및 실행
docker run --name es01 --net elastic -p 9200:9200 -it -m 1GB docker.elastic.co/elasticsearch/elasticsearch:8.16.0
# 비밀번호 알아내기
docker logs es01
# https 통신 가능하게 crt 내 컴퓨터로 복사
docker cp es01:/usr/share/elasticsearch/config/certs/http_ca.crt .
# 통신 테스트 http_ca.crt 는 crt 복사한 파일입니다. 이 파일이 있는 곳에 이 명령어를 입력해주세요.
curl --cacert http_ca.crt -u elastic:알아낸비밀번호 https://localhost:9200
{
"name" : "b4471643defe",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "6gFC2ruZRuK_DCxNc-AzSw",
"version" : {
"number" : "8.16.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "12ff76a92922609df4aba61a368e7adf65589749",
"build_date" : "2024-11-08T10:05:56.292914697Z",
"build_snapshot" : false,
"lucene_version" : "9.12.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
설치는 완료 됐습니다~
ElasticSearch 데이터 넣기
이제 간단하게 데이터를 넣어보도록 합시다.
먼저 데이터를 저장할 index 를 정의해야합니다.
url 을 보면 https://localhost:9200/my_index my_index 가 보입니다. 이것에 아래에 mappings 에 매칭하도록 설정한다는 의미입니다.
curl --cacert http_ca.crt -u elastic:내비밀번호 -X PUT "https://localhost:9200/my_index" -H "Content-Type: application/json" -d '{ "settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"title": { "type": "text" },
"description": { "type": "text" },
"created_at": { "type": "date" }
}
}
}'
이제 데이터를 넣어봅시다.
title: First Document
description: This is a sample document
created_at: 2024-11-16
curl --cacert http_ca.crt -u elastic:내비밀번호 -X POST "http://localhost:9200/my_index/_doc/" -H "Content-Type: application/json" -d '{ "title": "First Document",
"description": "This is a sample document",
"created_at": "2024-11-16"
}'
title: Second Document
description: This is a sample second document
created_at: 2024-11-17
curl --cacert http_ca.crt -u elastic:내비밀번호 -X POST "https://localhost:9200/my_index/_doc/" -H "Content-Type: application/json" -d '{ "title": "Second Document",
"description": "This is a sample for second document",
"created_at": "2024-11-17"
}'
2개의 데이터를 넣었습니다.
ElasticSearch 데이터 검색
검색을 해봅시다.
curl --cacert http_ca.crt -u elastic:내비밀번호 -X GET "https://localhost:9200/my_index/_search?pretty" -H "Content-Type: application/json" -d '{
"query": {
"match_all": {}
}
}'
{"took":47,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":0.6931471,"hits":[{"_index":"my_index","_id":"xAr4M5MBgm7TPf9eZ4WY","_score":0.6931471,"_source":{
"title": "Second Document",
"description": "This is a sample for second document",
"created_at": "2024-11-17"
}}]}}
이렇게 잘 검색되는 게 보입니다.
본격적인 대용량 테스트
2개의 데이터로는 Elasticsearch가 잘 작동하는 것을 확인할 수 있습니다. 하지만 여기서 끝내면 조금 아쉬운 감이 있습니다.
"정말 엄청난 양의 데이터가 존재할 때도 원하는 대로 빠르게 응답을 받을 수 있을까?"라는 의문이 들기 마련입니다. 이를 확인하기 위해, 테스트 목적으로 약 1000만 개의 데이터를 생성하여 검색 성능을 검증해 보려고 합니다.
대량의 데이터를 어떻게하면 ElasticSearch 에 넣을 수 있을까요? ElasticSearch 는 대량으로 데이터를 넣을 수 있는 방법이 있습니다.
curl --cacert http_ca.crt -u elastic:비밀번호 -X POST "https://localhost:9200/_bulk" -H "Content-Type: application/json" --data-binary @bulk_data.json
json 형태의 파일을 이용해서 대량의 데이터를 넣을 수 있습니다.
json 파일의 형태는 아래와 같아야합니다.
{ "index": { "_index": "my_index" } }
{ "title": "First Document", "description": "This is a sample document", "created_at": "2024-11-16" }
{ "index": { "_index": "my_index" } }
{ "title": "Second Document", "description": "This is another sample document", "created_at": "2024-11-17" }
index 를 정의하는 줄, 그 다음줄은 그 index 에 들어가야하는 데이터. 이런 형태로 json 파일을 정의해야합니다.
데이터 생성
1000만 개의 데이터를 생성하려고 합니다.
데이터를 만들기 전에, 데이터의 형태를 다음과 같이 정의해 보려고 합니다.
id: integer
title: string 50글자 최대
description: string 200글자 최대
created_at: datetime
updated_at: datetime
이 많은 데이터를 만들기 위해서 Python 의 faker 를 이용하려고 합니다.
import json
from faker import Faker
from datetime import timedelta
# Faker 초기화
fake = Faker()
# Bulk API 데이터를 생성하는 함수
def generate_bulk_data(_index_name, _num_records):
bulk_data = []
for i in range(1, _num_records + 1):
if i % 1000 == 0:
print(i, "records generated.")
# 날짜 생성
created_at = fake.date_time_between(start_date='-2y', end_date='now')
updated_at = created_at + timedelta(days=fake.random_int(min=0, max=30))
# 메타데이터
bulk_data.append({"index": {"_index": _index_name}})
# 데이터 레코드
record = {
"id": i,
"title": fake.text(max_nb_chars=50).strip('.'),
"description": fake.text(max_nb_chars=200).strip('.'),
"created_at": created_at.isoformat(),
"updated_at": updated_at.isoformat()
}
bulk_data.append(record)
return bulk_data
# JSON Lines 형식으로 변환
def to_json_lines(_bulk_data):
lines = []
for item in _bulk_data:
if item.get('id', 1) % 1000 == 0:
print(item['id'], "made as json line.")
lines.append(json.dumps(item, ensure_ascii=False))
return "\n".join(lines)
# Bulk 데이터 생성
index_name = "test_index"
num_records = 10000000
bulk_data = generate_bulk_data(index_name, num_records)
# JSON Lines 형식 데이터
bulk_json = to_json_lines(bulk_data)
# JSON Lines 파일로 저장
with open("bulk_data.json", "w", encoding="utf-8") as f:
f.write(bulk_json)
데이터 생성은 보통 Python의 Faker 라이브러리를 사용해 무작위 데이터를 만들어 진행합니다. 하지만 1000만 개 정도의 데이터를 생성하려면 시간이 꽤 걸립니다. 제가 테스트했을 때는 약 10분 정도가 소요되었습니다.
데이터 생성이 진행되는 동안에는 잠시 여유를 가지는 것도 좋은 방법입니다. 한 번 실행한 후에는 유튜브를 보거나 차 한 잔 마시면서 기다리면 충분한 시간이 됩니다.
생성된 데이터 ElasticSearch 삽입
index를 생성합니다.
# 내가 설정한 index 이름 잘 확인하세요 JSON 에 정의한 index 부분 /test_index 로 저는 정의했었습니다.
curl --cacert http_ca.crt -u elastic:내비밀번호 -X PUT "https://localhost:9200/test_index" -H "Content-Type: application/json" -d '{ "settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": { "type": "long" },
"title": { "type": "text" },
"description": { "type": "text" },
"created_at": { "type": "date" },
"updated_at": { "type": "date" }
}
}
}'
현재 JSON 데이터는 1개의 파일로 모두 합쳐진 상태일 것입니다. 하지만, 이 파일을 한꺼번에 ElasticSearch에 삽입하려고 하면 아래와 같은 에러가 발생할 수 있습니다.
curl --cacert http_ca.crt -u elastic:비밀번호 -X POST "https://localhost:9200/_bulk" -H "Content-Type: application/json" --data-binary @bulk_data.json
curl: option --data-binary: out of memory
curl: try 'curl --help' or 'curl --manual' for more information
JSON 파일의 용량이 너무 커서 ElasticSearch로 데이터를 삽입하려 할 때 Out of Memory 에러가 발생했습니다.
현재 JSON 파일의 크기가 약 3.3GB 정도로, 한 번에 처리하기에는 너무 큰 상태입니다.
이 문제를 해결하기 위해, JSON 파일을 여러 개의 작은 파일로 분할할 계획입니다. 이렇게 하면 한 번에 처리해야 할 데이터의 양이 줄어들어 Out of Memory 문제를 방지할 수 있습니다.
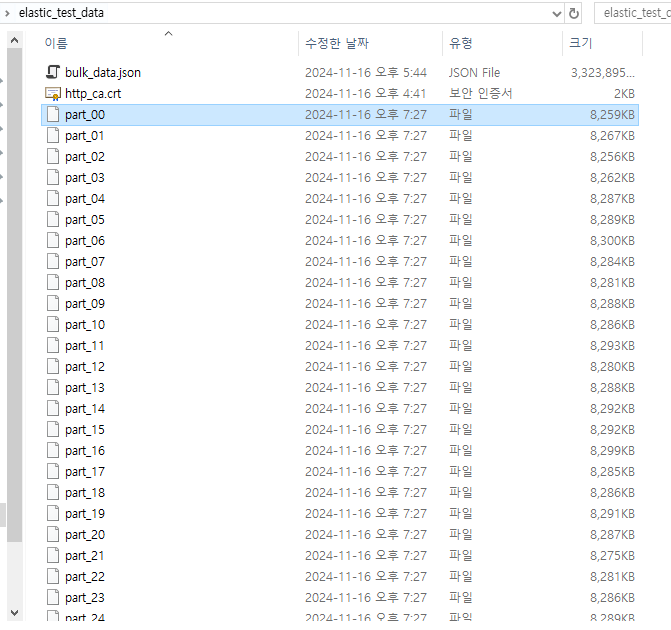
split -l 50000 --numeric-suffixes bulk_data.json part_
생성된 JSON 파일을 기준으로, 50,000줄씩 분할하여 part_라는 이름으로 여러 개의 파일을 생성하는 명령어입니다.
이 명령어를 실행하면 아래와 같이 많은 파일이 생성됩니다.
이 작업을 자동화하기 위해 sh 파일을 만들어서, 반복적으로 JSON 데이터를 ElasticSearch에 삽입할 수 있도록 설정합니다. 이렇게 하면 대량 데이터를 효율적으로 처리할 수 있습니다.
set_my_json_to_elasticsearch.sh
for file in part_*; do
echo "Uploading $file..."
curl --cacert http_ca.crt -u elastic:비밀번호 -X POST "https://localhost:9200/_bulk" \
-H "Content-Type: application/json" \
--data-binary @"$file"
echo "Finished uploading $file"
done
실행합니다.
./set_my_json_to_elasticsearch.sh
엄청난 양의 데이터가 정말 빠르게 쑥쑥 들어가고 있습니다! 이제 잠시 기다리면서 결과를 기대해 봅시다.
이제, 많은 데이터가 제대로 들어갔는지 확인해 보겠습니다. 데이터가 예상대로 저장되었다면 이후 테스트도 순조롭게 진행될 수 있을 것 같습니다.
curl --cacert http_ca.crt -u elastic:비밀번호 -X GET "https://localhost:9200/test_index/_count?pretty"
{"count":9975000,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0}}
중간에 약간 문제가 생겨서 1000만 개의 데이터를 모두 삽입하지는 못했지만, 그래도 꽤 많은 데이터를 넣는 데 성공했습니다.
ElasticSearch 검색
이제 검색을 한번 해봅시다.
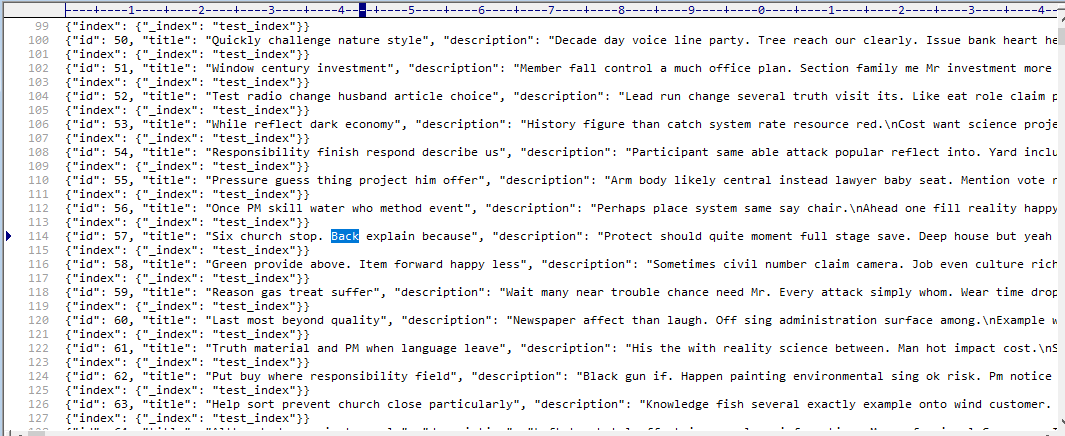
이제, 생성된 테스트 데이터에서 Back이라는 키워드를 검색해 보겠습니다. 정말로 id가 57인 데이터가 검색 결과에 포함될까요? Elasticsearch의 정확성과 성능을 확인할 수 있는 좋은 테스트가 될 것 같습니다.
curl --cacert http_ca.crt -u elastic:rfBZCHzQXOtpZmcR7Vtj -X GET "https://localhost:9200/test_index/_search?pretty" -H "Content-Type: application/json" -d '{
"size": 10,
"query": {
"match": {
"title": "Back"
}
},
"sort": [
{ "id": "asc" }
]
}'
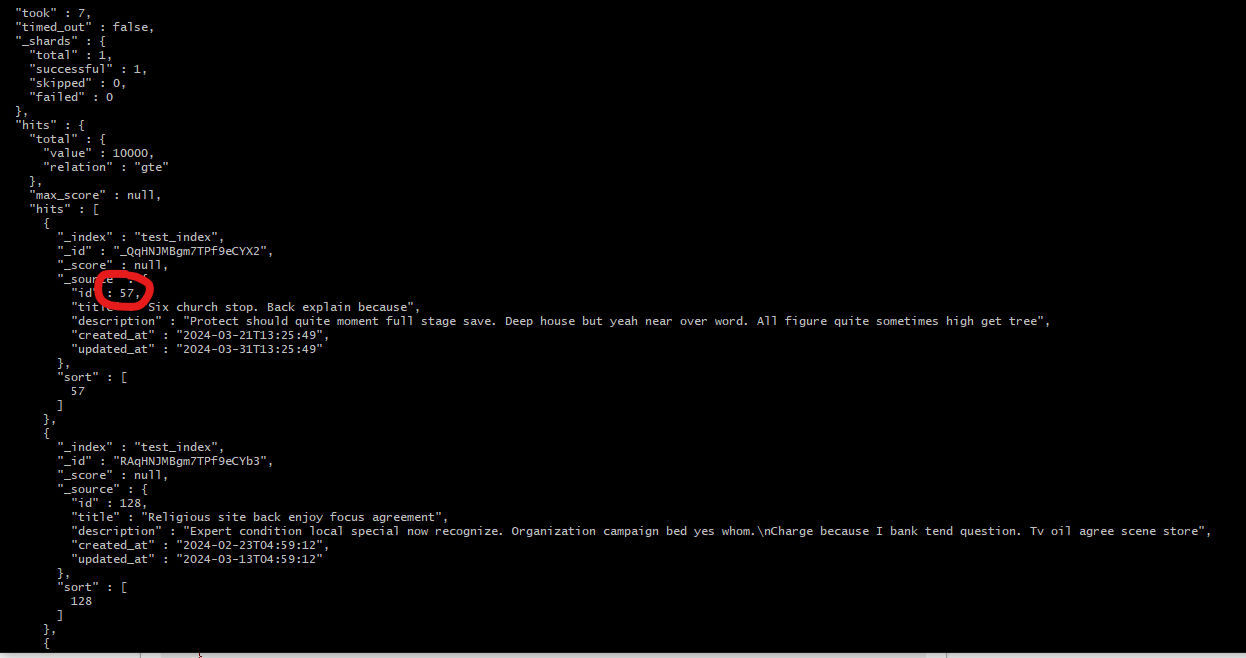
id 57이 나왔다!
검색 결과가 나오는 속도도 엄청 빠르고, 기대 이상으로 좋은 성능을 보여주는 것 같습니다.
나중에는 Django와 연동하여 데이터를 조회하는 방식도 확인해볼 계획입니다. Django와 ElasticSearch를 함께 사용하면 더 많은 가능성을 열 수 있을 것 같네요!