이창우 (Beany)
프로젝트 좋아, 코딩 좋아, 만드는 것 자체를 좋아하는 개발자 이창우 입니다~!
- 🔭 저는 현재 **Django/DRF/Python/백엔드** 개발을 하고 있어요. - 👯 백엔드, 프론트엔드 프로젝트에 함께 협업하고 싶어요. - 🤔 Java 관련해서 도움을 구하고 있습니다. - 📫 연락처: - **Kakao:** cwadvan - **Email:** cwadven@naver.com -  - Link -  - Link --- **Languages and Tools**





오늘의 Lesson
Elastic Search
1. 역색인 필드의 활용 ```json PUT /my_index { "mappings": { "properties": { "title": { "type": "text" }, "title_keyword": { "type": "keyword" } } } } POST /my_index/_search { "query": { "match": { "title_keyword": "Elasticsearch 초보" } } } ``` 2. 부분 일치 검색을 위한 Fuzzy Query 활용하기 ```json { "query": { "fuzzy": { "title": { "value": "Elasticserch", "fuzziness": "2" } } } ``` 3. Analyzers의 활용 ```json PUT /my_index { "settings": { "analysis": { "
✏ 최근 포스트
💌 좋아요 많은 게시글
Github Action workflow dispatch [Self Hosted]
버튼 클릭으로 GitHub Action을 실행하고 싶었습니다.
GitHub Action을 실행하는 방법에는 push로 자동 실행하거나, 버튼을 클릭하여 수동으로 실행하는 방식이 있습니다.
push 방식의 단점은 단 한 번만 실행된다는 점입니다.
물론 실패한 Action이라면 다시 재실행할 수 있지만, 그럼에도 불구하고 버튼 클릭 방식이 본래의 목적에 더 부합한다고 생각했습니다.
그래서 버튼 클릭으로 GitHub Action을 실행하는 방법을 개발하고, 이를 기록해두려 합니다.

테스트는 제가 개인 프로젝트로 진행 중인 Qosmo-API를 대상으로 생성할 예정입니다.
https://github.com/cwadven/Qosmo-API/actions
[참고사항]
GitHub Action을 설치하기 위해 self-hosted runner를 사용했습니다.
sudo 명령어를 실행할 수 있도록 하기 위해, runner 설정 시 아래와 같이 명령어를 실행했습니다:
# sudo 권한으로 전부 실행
sudo su -
# 다운로드 받은 파일 위치로 가기
sudo RUNNER_ALLOW_RUNASROOT="1" ./config.sh --url https://github.com/cwadven/Qosmo-API --token xxxxxxxxxxxxxxxxxxxx
sudo RUNNER_ALLOW_RUNASROOT="1" ./run.sh
sudo RUNNER_ALLOW_RUNASROOT="1" ./svc.sh install
sudo RUNNER_ALLOW_RUNASROOT="1" ./svc.sh start
# 잘되는지 확인
sudo RUNNER_ALLOW_RUNASROOT="1" ./svc.sh status
# 만약 status 부분에서 에러가 난다면 권한 수정이 필
sudo chown -R $(whoami):$(whoami) /path/to/actions-runner
chmod -R 755 /path/to/actions-runner
지금은 Actions 탭에 들어가도, 위에서 설명한 workflow_dispatch 기능이 보이지 않습니다.
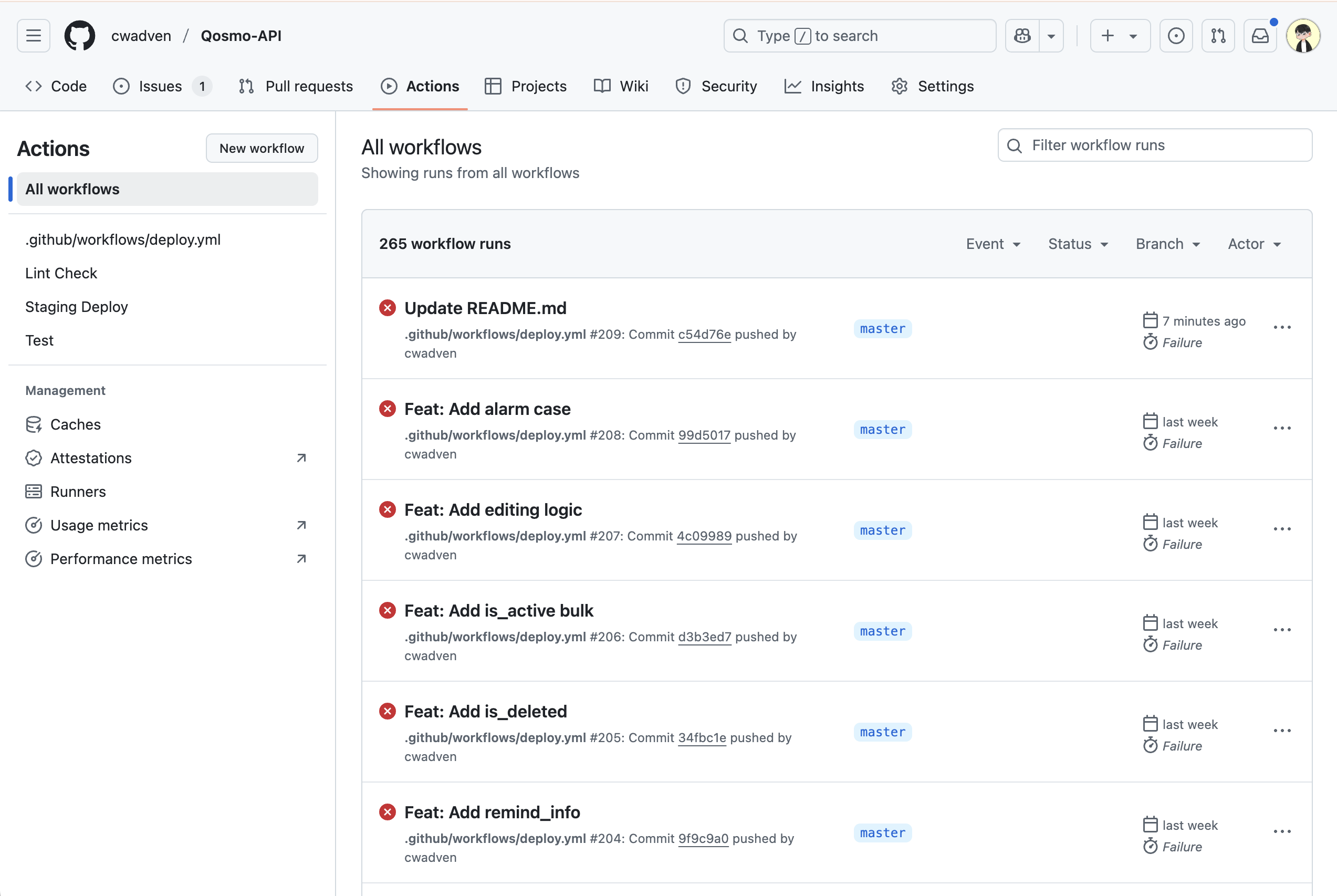
workflow_dispatch 기능을 적용하면, 버튼 클릭으로 GitHub Action을 수동 실행할 수 있습니다.
프로젝트 루트 디렉터리에 .github/workflows/deploy.yml 파일을 생성합니다.

1단계: workflow_dispatch를 적용합니다
저는 deployment-type이라는 이름으로 input 값을 받을 예정이며, 이 값을 기반으로 어떤 서버에 배포할지 결정하려고 합니다.
(지금은 라이브 밖에 없어서 productino 만 넣습니다.)
name: Deploy
on:
workflow_dispatch:
inputs:
deployment-type:
type: choice
description: 'Which server to deployment type'
required: true
default: 'production'
options:
- production
짜잔 생겼습니다~
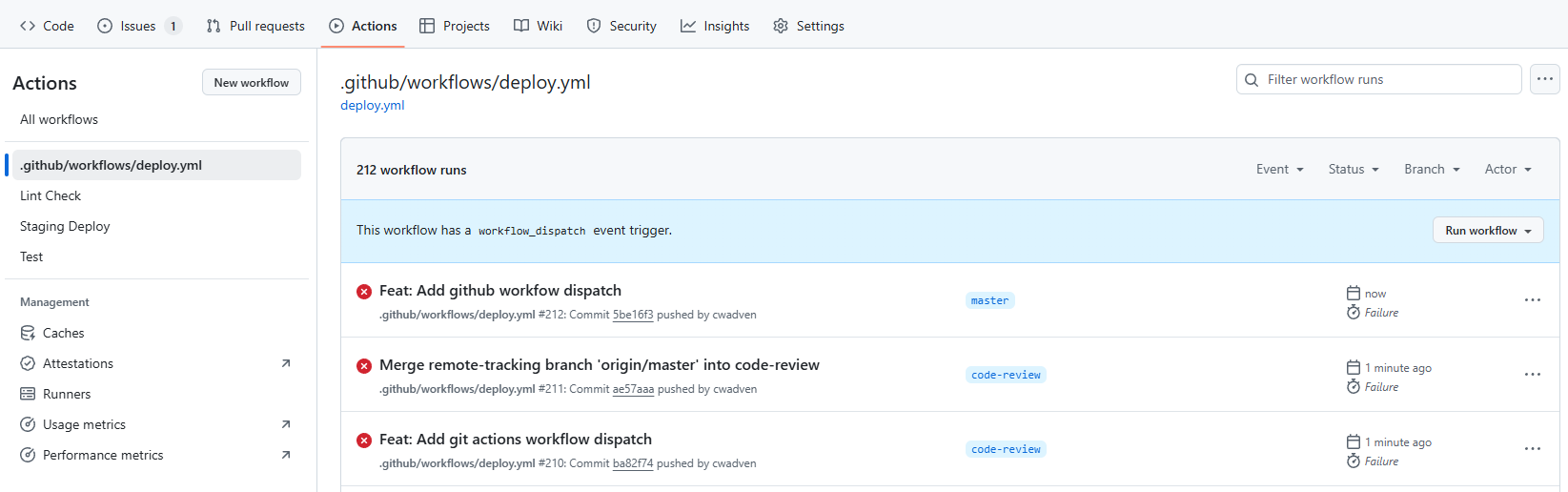
이렇게도 나왔네요.
이제 배포 스크립트를 작성하기 전에, 여러 사람이 동일한 action 방지를 위해서 concurrency 를 보장하기 위해 아래와 같이 넣습니다.
name: Deploy
on:
workflow_dispatch:
inputs:
deployment-type:
type: choice
description: 'Which server to deployment type'
required: true
default: 'production'
options:
- production
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
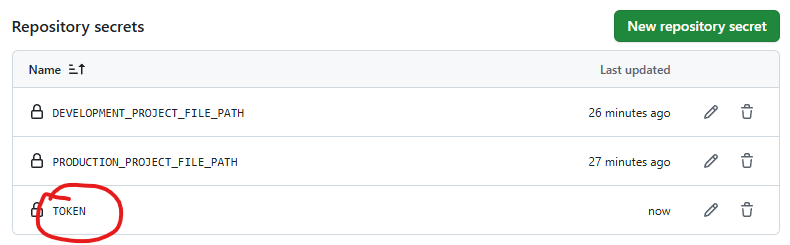
github action 에서 쓸 Secret 을 Actions Secret 에 정의하고 시작 합시다.
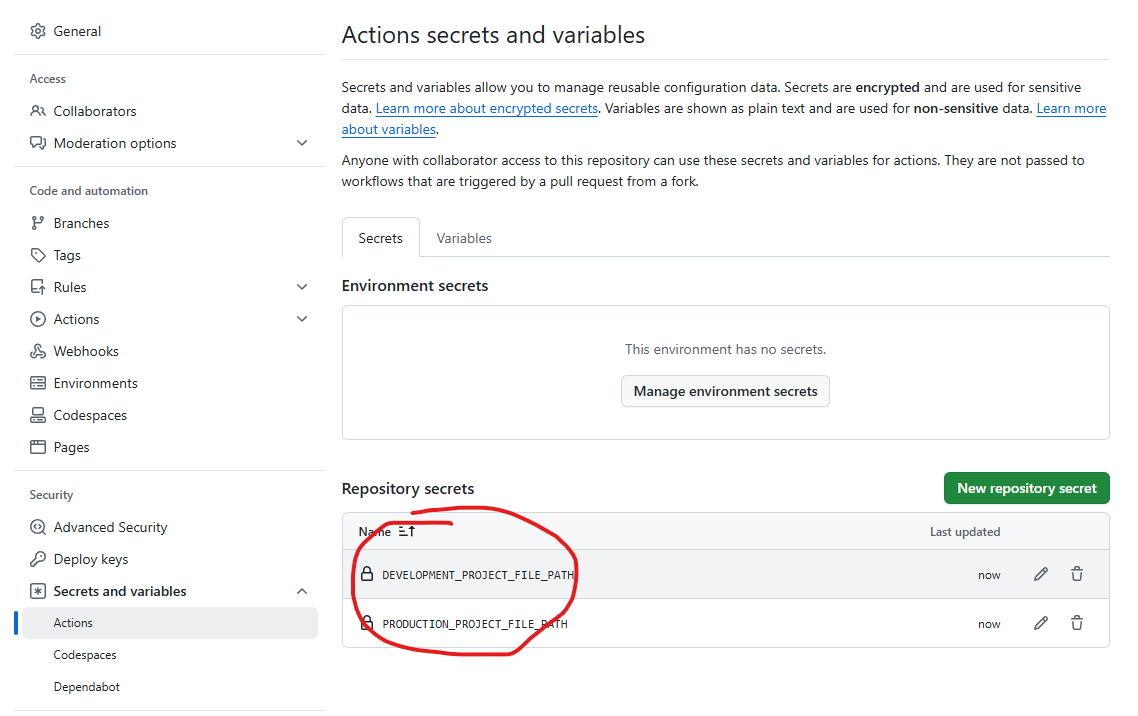
github 에 접근 권한이 있어야하기 때문에 github token 도 생성합니다.
Settings 에서 Developer settings 접속
Tokens 접속
Generate new token 클래식
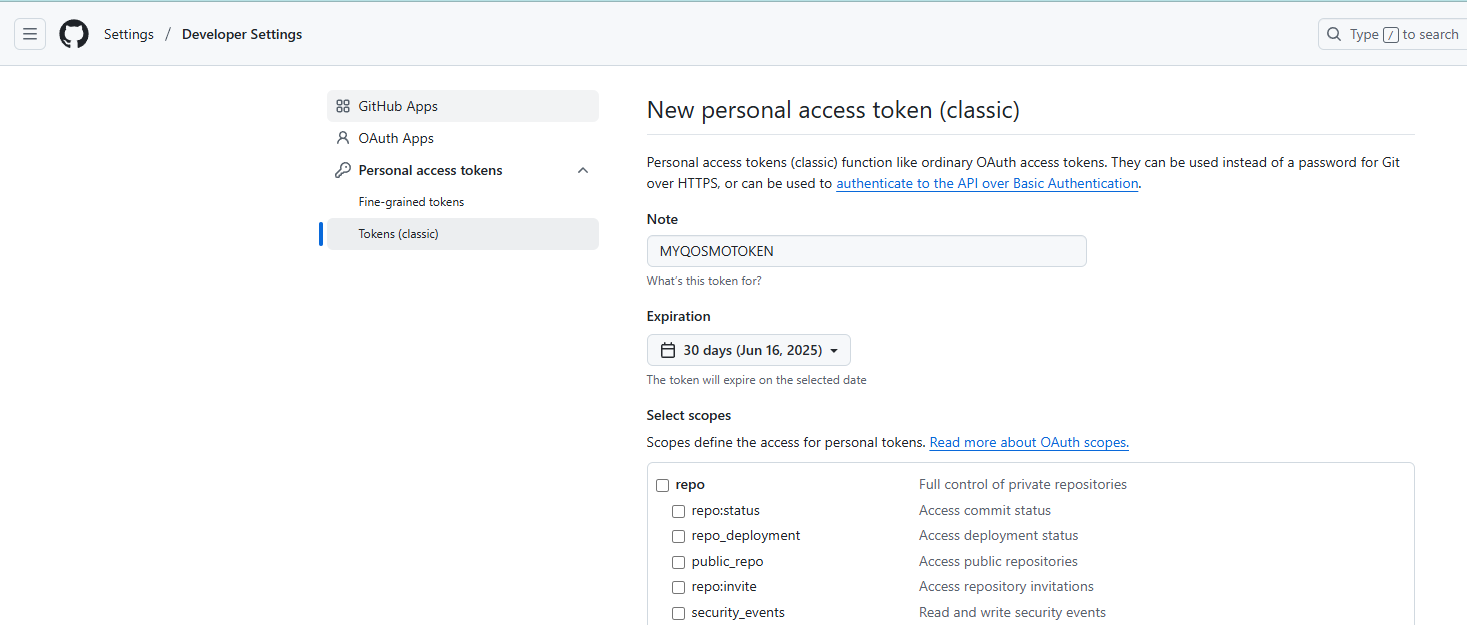
권한 다 체크 한 후, 생성합니다.
생성된 토큰을 github action 에서 쓸 Secret 에 추가로 등록합니다.
자 이제 그럼 배포를 하기 위해서 배포 flow 에 필요한 명령어를 작성해 봅시다.
name: Deploy
on:
workflow_dispatch:
inputs:
deployment-type:
type: choice
description: 'Which server to deployment type'
required: true
default: 'production'
options:
- production
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
env:
DJANGO_SETTINGS_MODULE: "config.settings.production"
jobs:
setup-git:
runs-on: self-hosted
steps:
- name: Set Safe Directory
run: |
git config --global --add safe.directory "${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}"
pull-code:
needs: setup-git
runs-on: self-hosted
env:
GITHUB_TOKEN: ${{ secrets.TOKEN }}
steps:
- name: Pull Branch
run: |
cd ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }} && sudo git checkout ${{ github.ref }} && sudo git pull origin ${{ github.ref }}
update-dependencies:
needs: pull-code
runs-on: self-hosted
steps:
- name: pip Update
run: |
cd ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }} && . ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/venv/bin/activate && pip install -r ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/requirements.txt
collect-static:
needs: update-dependencies
runs-on: self-hosted
steps:
- name: Collectstatic
run: |
cd ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }} && . ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/venv/bin/activate && python ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/manage.py collectstatic --noinput
database-migrate:
needs: collect-static
runs-on: self-hosted
steps:
- name: Database Update
run: |
cd ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }} && . ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/venv/bin/activate && python ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/manage.py migrate --noinput
update-cron:
needs: database-migrate
runs-on: self-hosted
steps:
- name: cronjob command update
run: |
cd ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }} && . ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/venv/bin/activate && fab2 update-crontab
continue-on-error: true
restart-cron:
needs: update-cron
runs-on: self-hosted
steps:
- name: cronjob restart
run: |
cat ${{ secrets.PRODUCTION_PROJECT_FILE_PATH }}/command.cron | sudo crontab -
sudo /etc/init.d/cron reload
continue-on-error: true
restart-celery:
needs: restart-cron
runs-on: self-hosted
steps:
- name: celery restart
run: |
sudo /etc/init.d/celeryd restart
continue-on-error: true
restart-web-server:
needs: restart-celery
runs-on: self-hosted
steps:
- name: Restart web server
run: |
sudo systemctl restart nginx
sudo systemctl restart gunicorn
위와 같이 정의했습니다.
작동을 시키니 아주 잘 돌아갑니다.
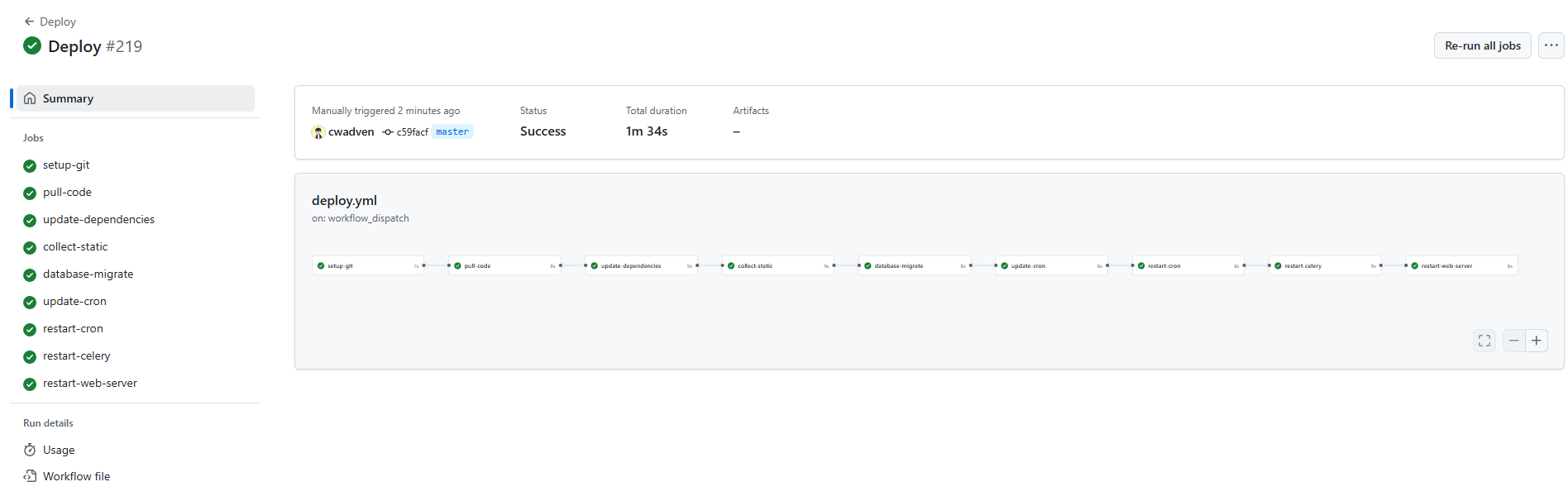
이제 버튼 클릭으로 스테이징 배포 혹은 라이브 배포가 가능합니다.
지금은 self hosted 를 라이브 서버에 설치해서 라이브든 스테이징이든 라이브가 배포되겠지만 이걸 한번더 나누려면 self hosted 를 나눠서 설정하면 될것 같습니다.
python 구글 드라이브 파일 업로드 기능 개발
Google Drive에 파일을 업로드하는 과정을 총 6단계로 나누어 설명하려고 합니다.
- 로직 구현을 위한 파일 및 폴더 생성
- Google Cloud 프로젝트 생성 및 API 활성화
- 사용자 인증 정보 설정
- Google Drive에 데이터 저장용 폴더 생성
- 로직 구현을 위한 의존성 라이브러리 설치 및 코드 구현
- 코드 실행
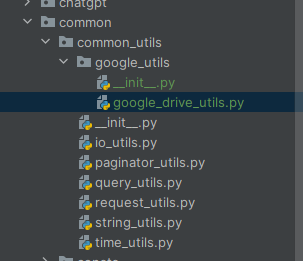
1. 로직 구현을 위한 파일 및 폴더 생성
common/common_utils 패키지 내부에 google_utils를 생성하고, google_drive_utils.py 파일을 추가했습니다.
2. Google Cloud 프로젝트 생성 및 API 활성화
https://cloud.google.com/?hl=ko
(Google Drive API Docs: https://developers.google.com/drive/api/reference/rest/v3?apix=true&hl=ko)
API 및 서비스 메뉴에서 라이브러리로 접근합니다.
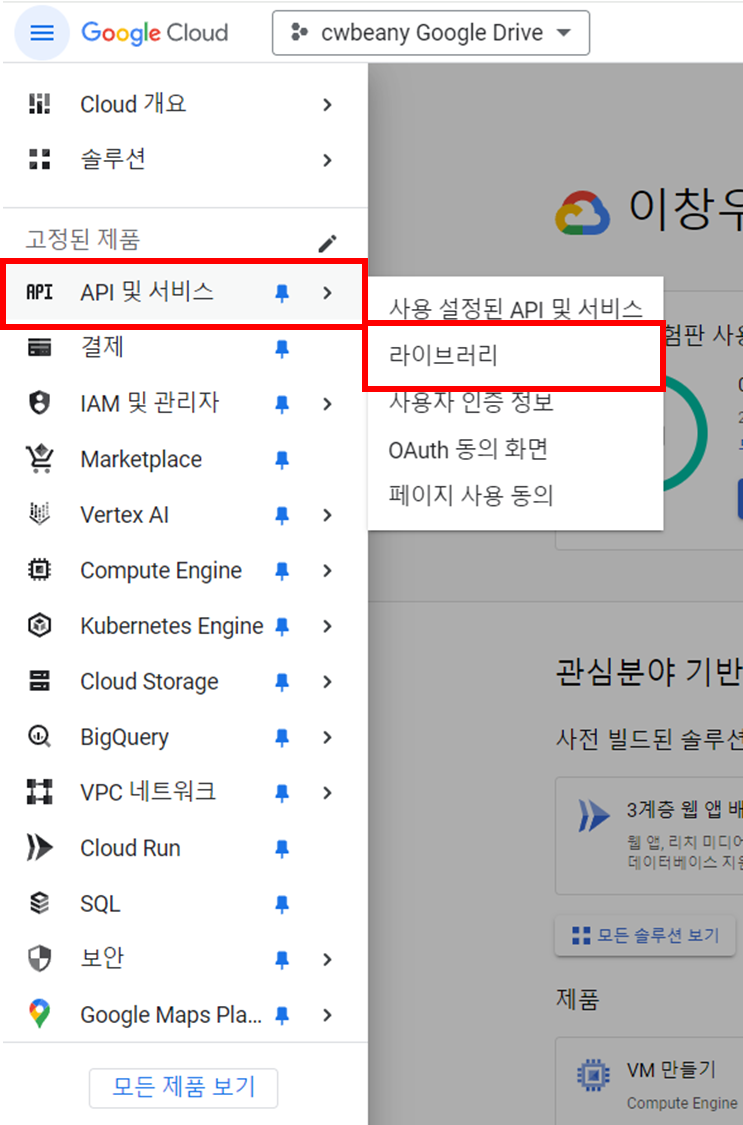
Google Drive API를 검색합니다.
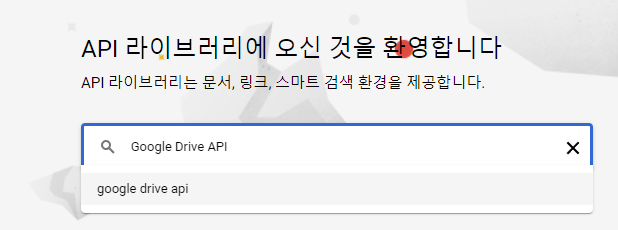
Google Drive API 를 선택합니다.
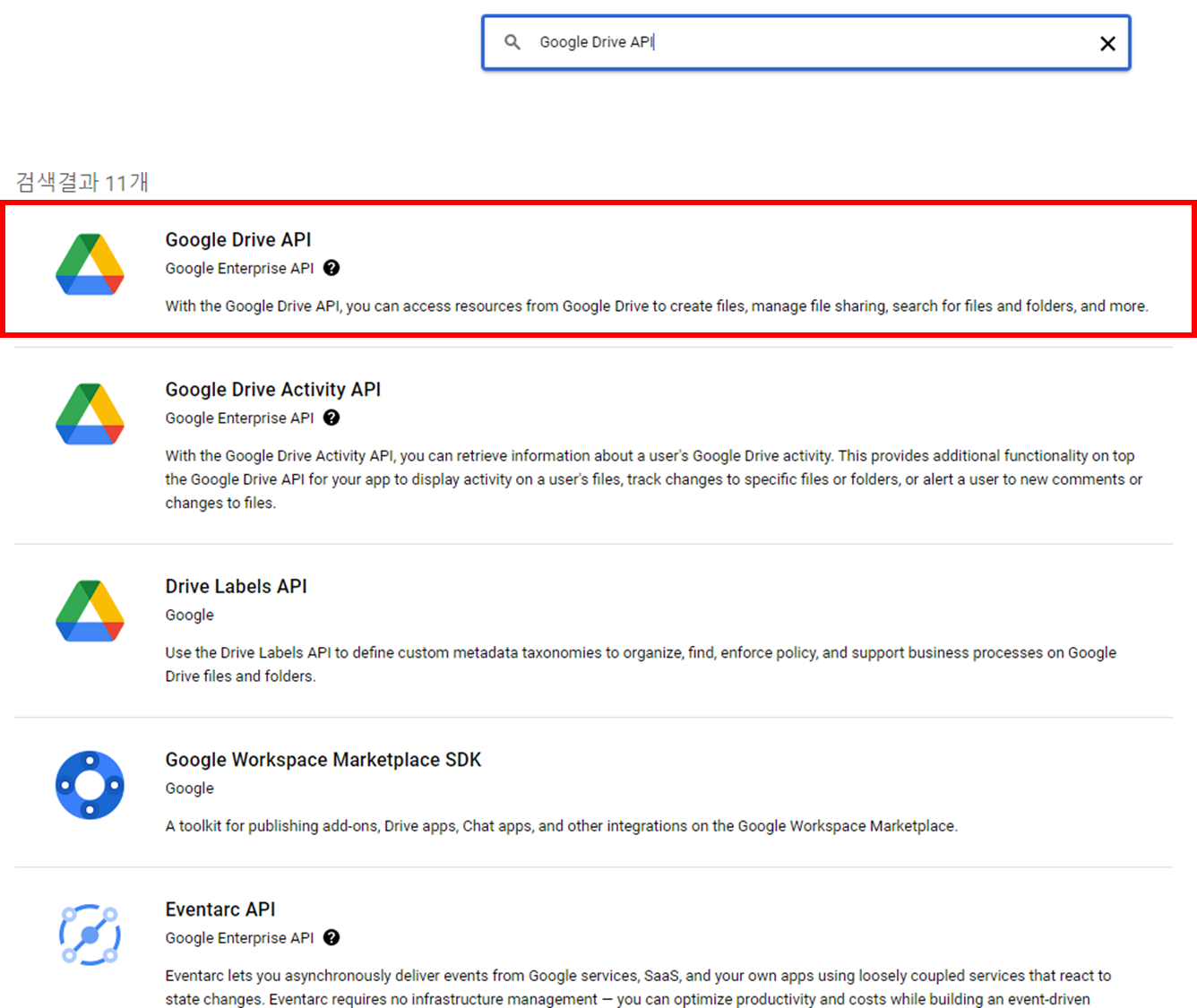
사용 클릭~!
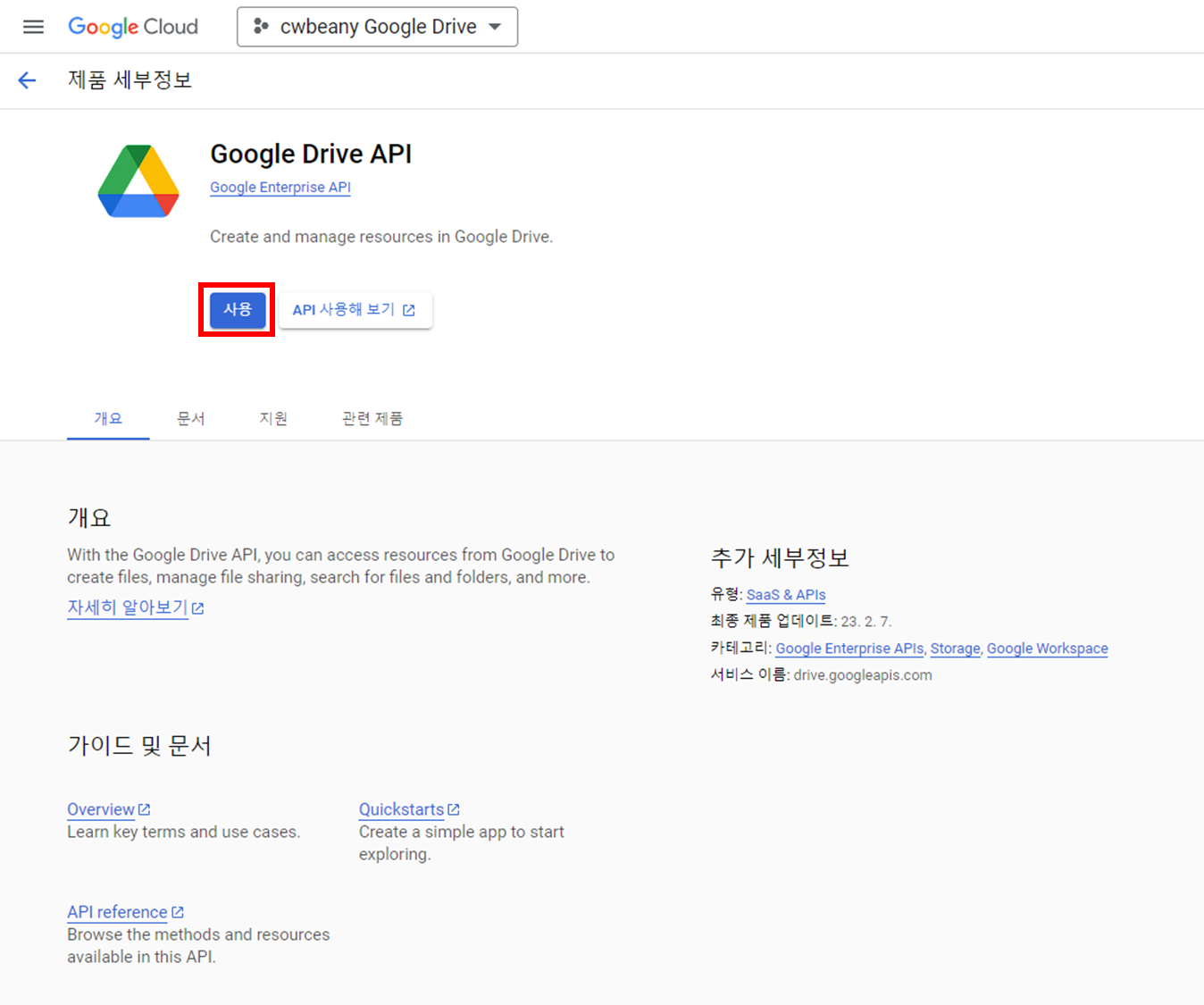
잠시 기다리면 설정이 완료됩니다~
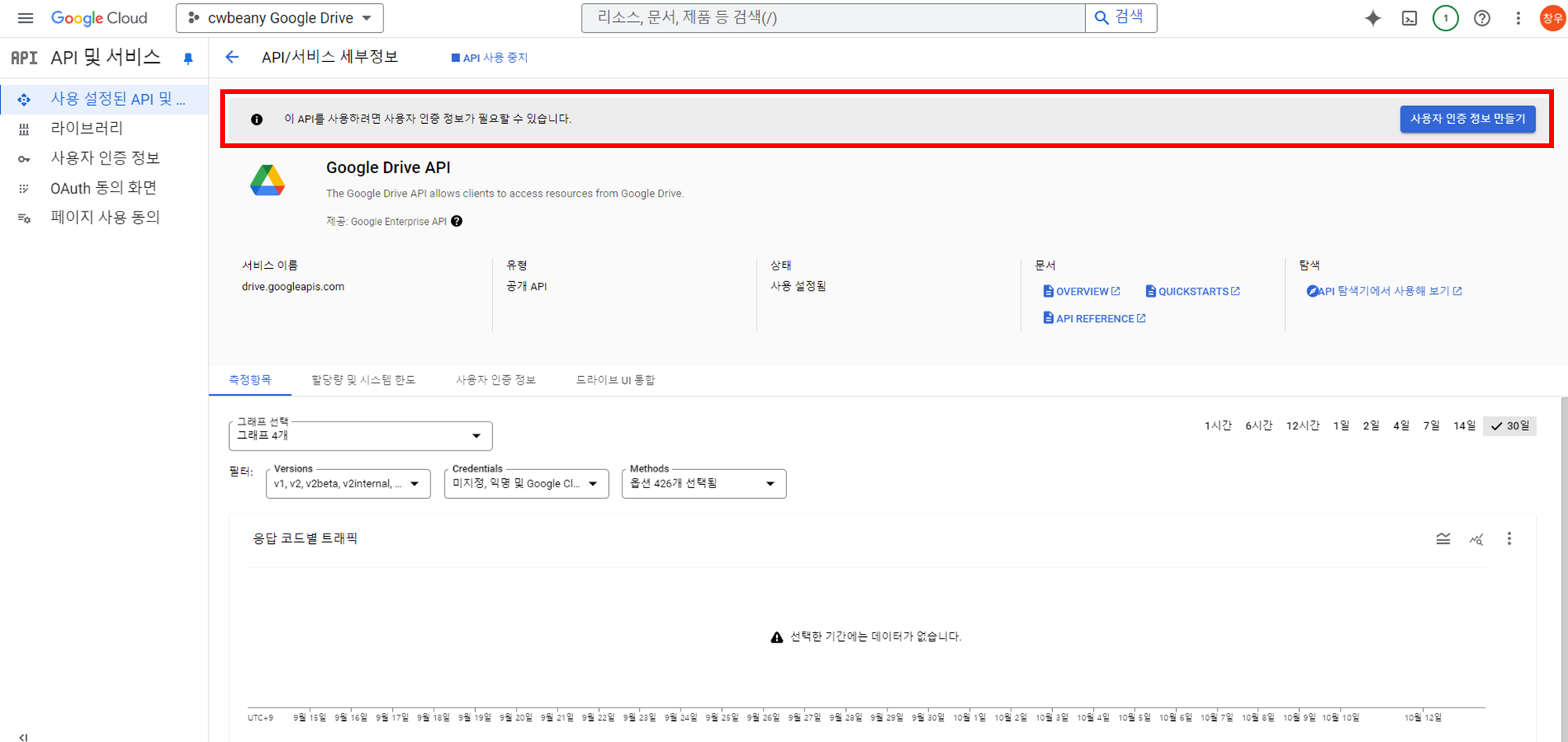
이제 이 API를 사용하려면 사용자 인증 정보가 필요하므로, 사용자 인증 정보를 생성합시다.
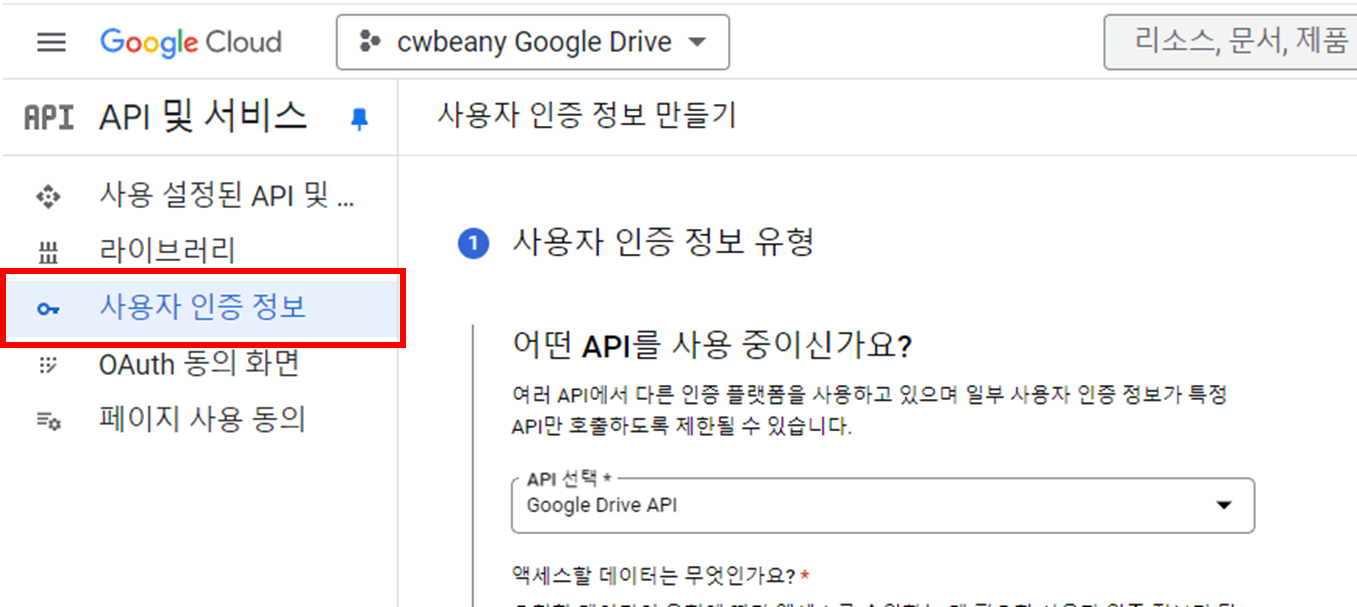
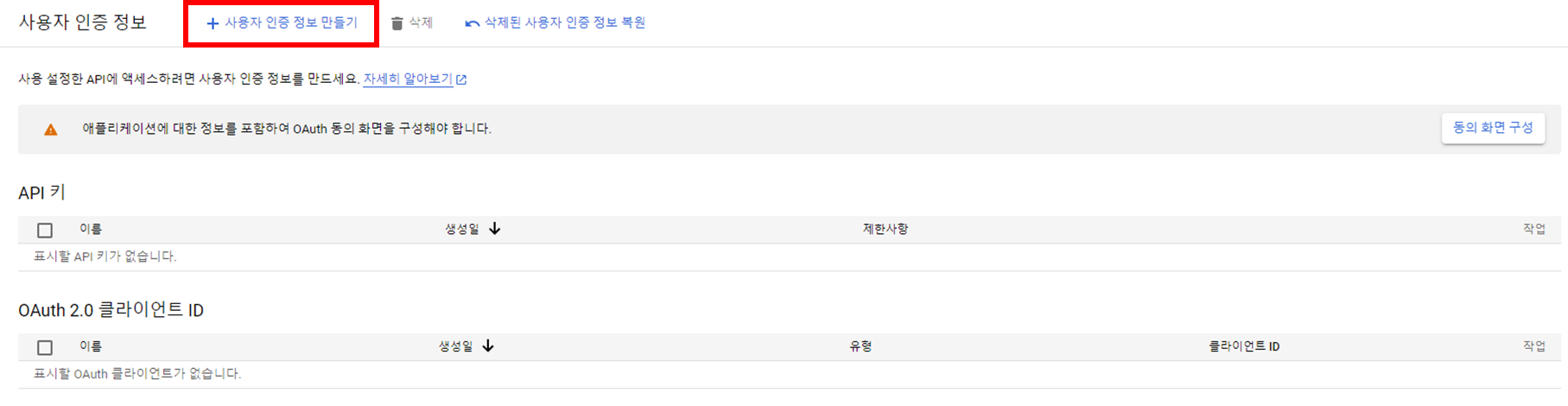
3. 사용자 인증 정보 설정
API를 Google Drive API로 설정하고, 애플리케이션 데이터로 설정합니다. 이렇게 설정하는 이유는 파일을 저장하기 위한 목적이기 때문에 사용자의 데이터 접근이 필요하지 않기 때문입니다.
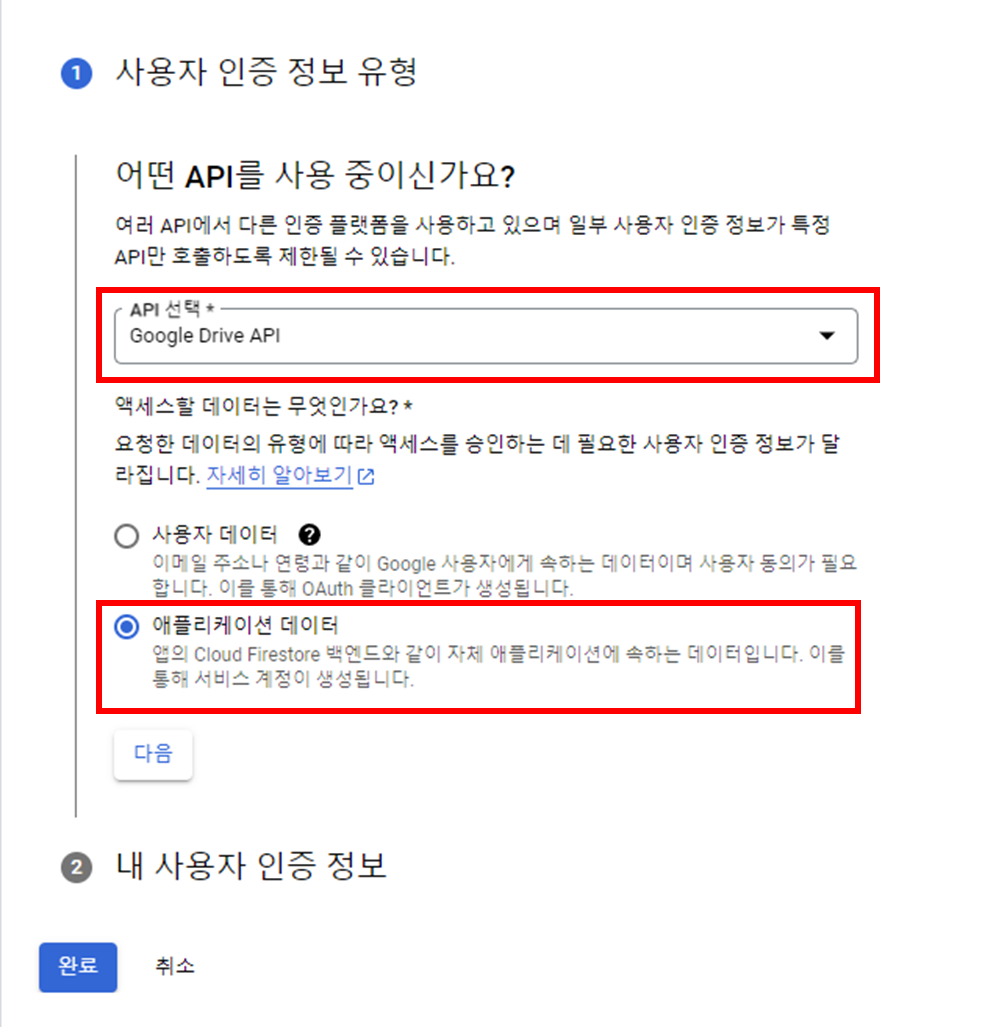
서비스 계정의 세부 정보를 설정합니다.
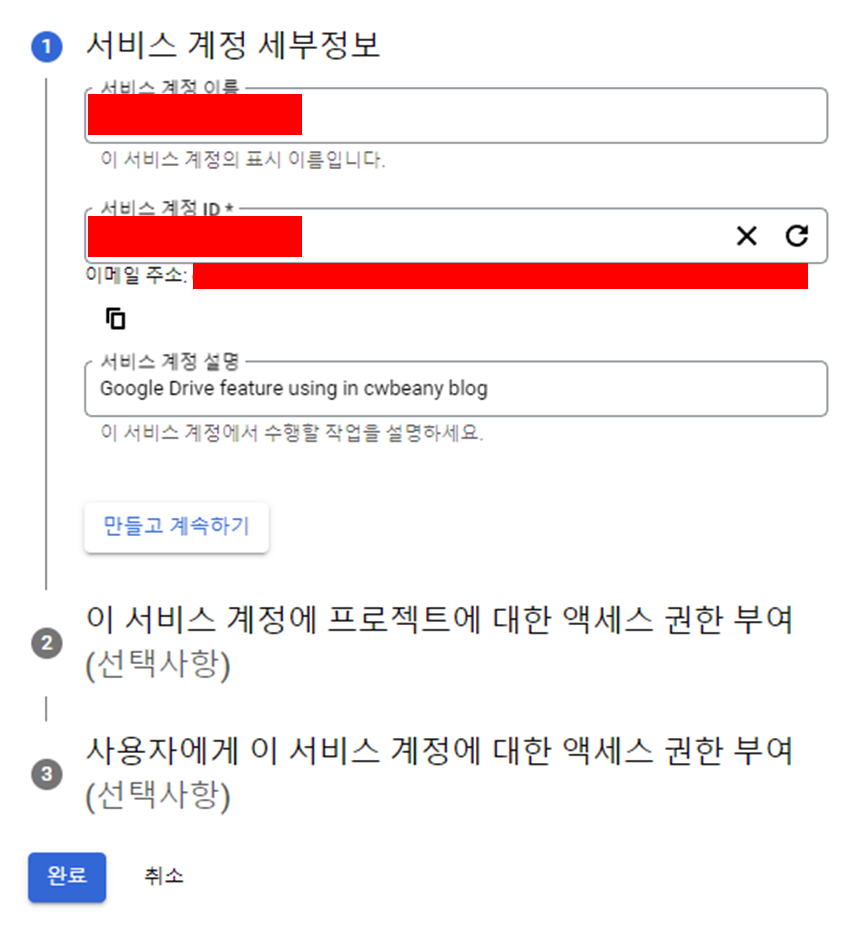
완료 클릭
생성한 서비스 계정에서 키 탭으로 이동하여 새로운 키를 생성합니다.
이 키는 서버에 저장할 예정이며, 이를 통해 서비스 계정 권한을 부여할 것입니다.
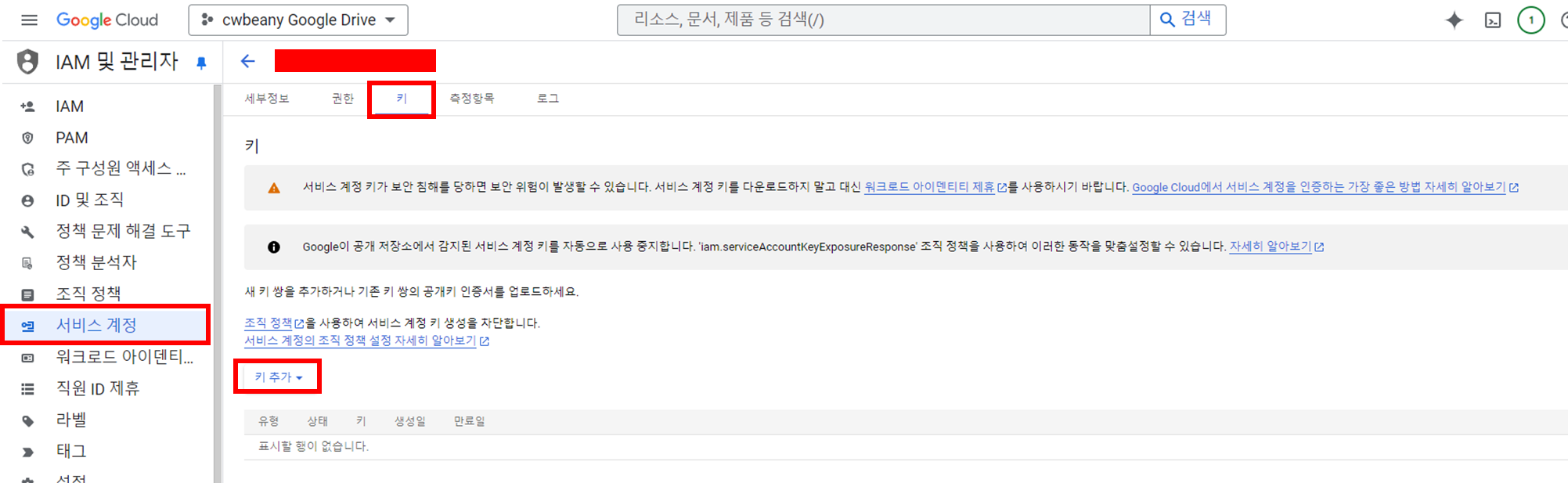
JSON 형태로 비공개 키를 생성합니다.

만들어진 파일을 잘 저장합니다.
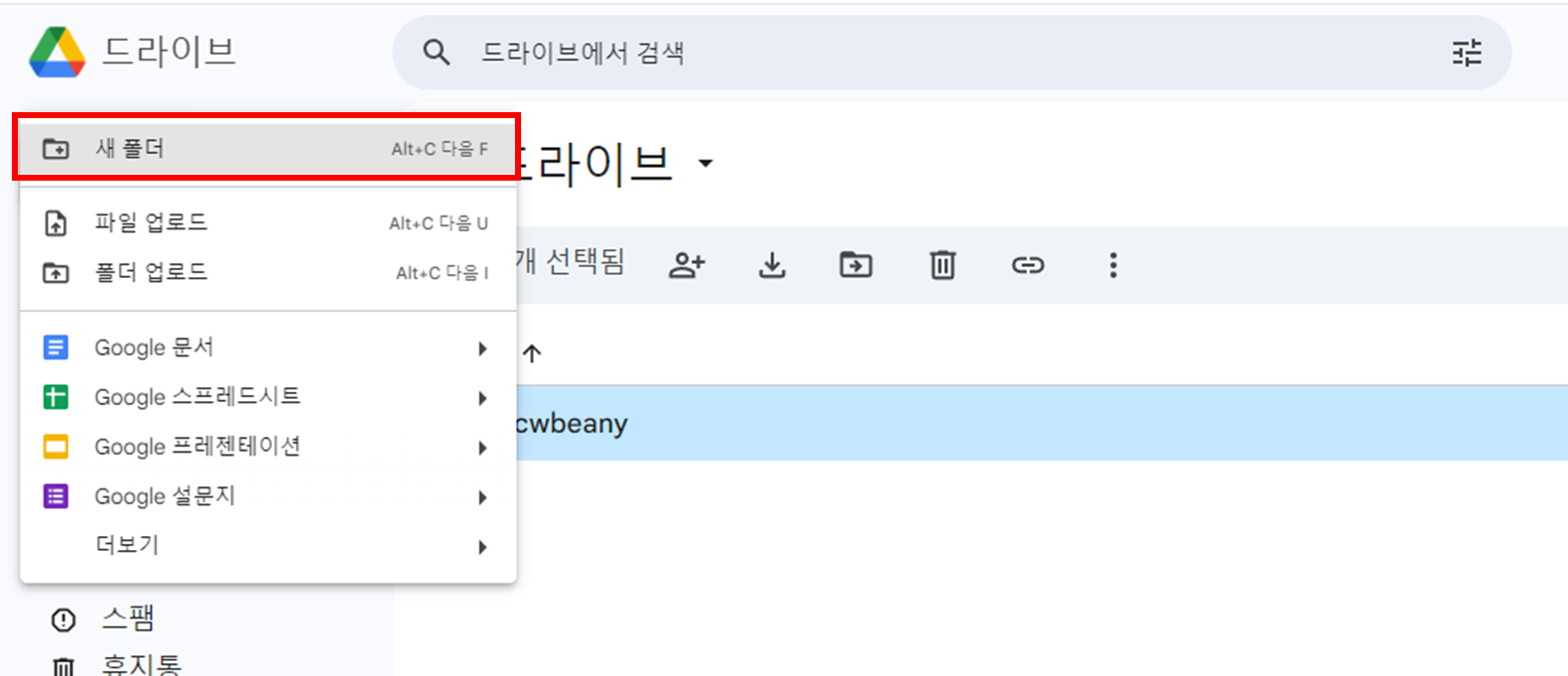
4. Google Drive에 데이터 저장용 폴더 생성
폴더를 생성합니다.
만든 폴더를 공유합니다.
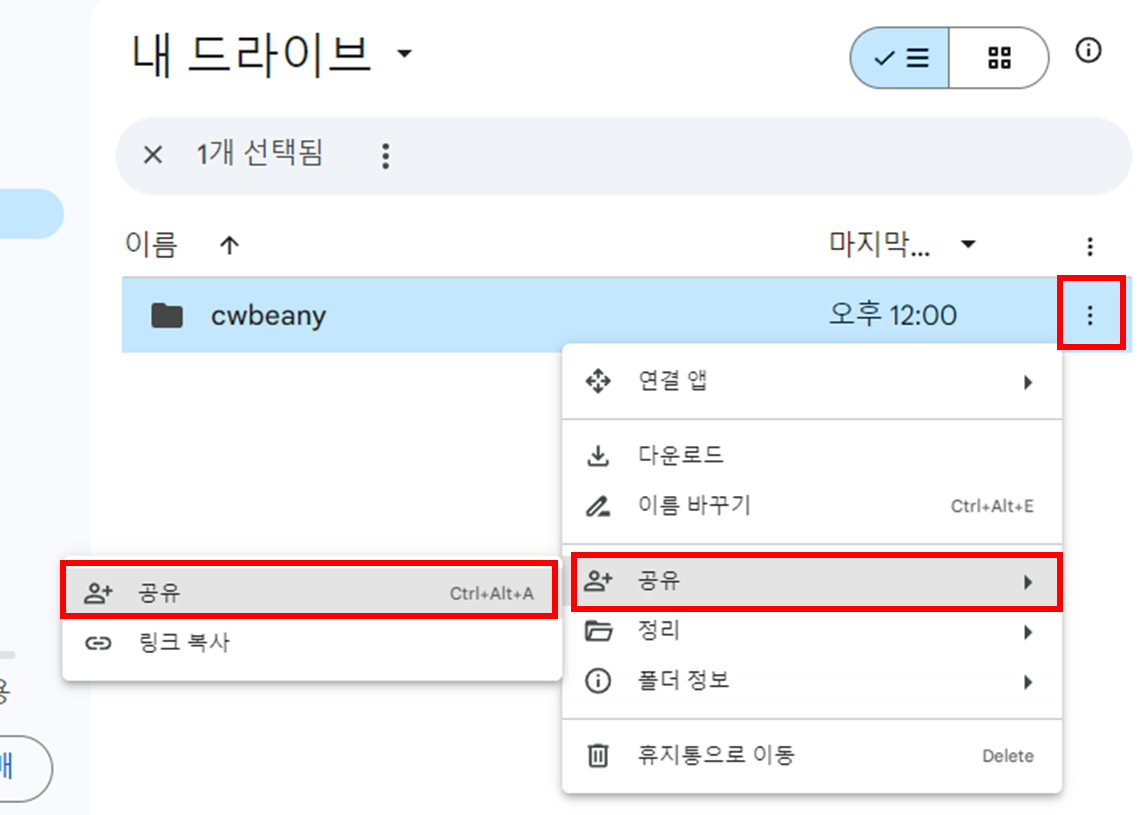
위에 권한을 주기 위해 만들어진 서비스 계정 세부 정보의 주소(3. 사용자 인증 정보 설정 참고)를 넣습니다.

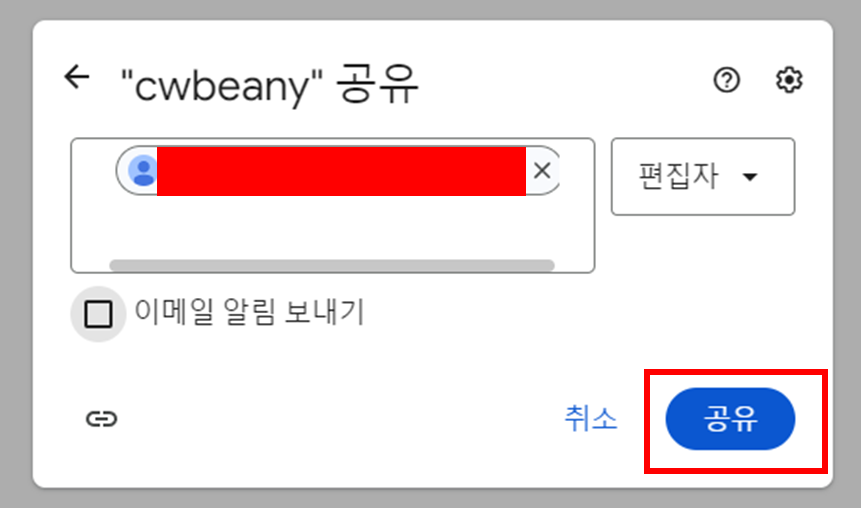
공유합니다.
이제 해당 폴더에 들어가서 주소 folders 뒤에 있는 정보를 복사합니다.
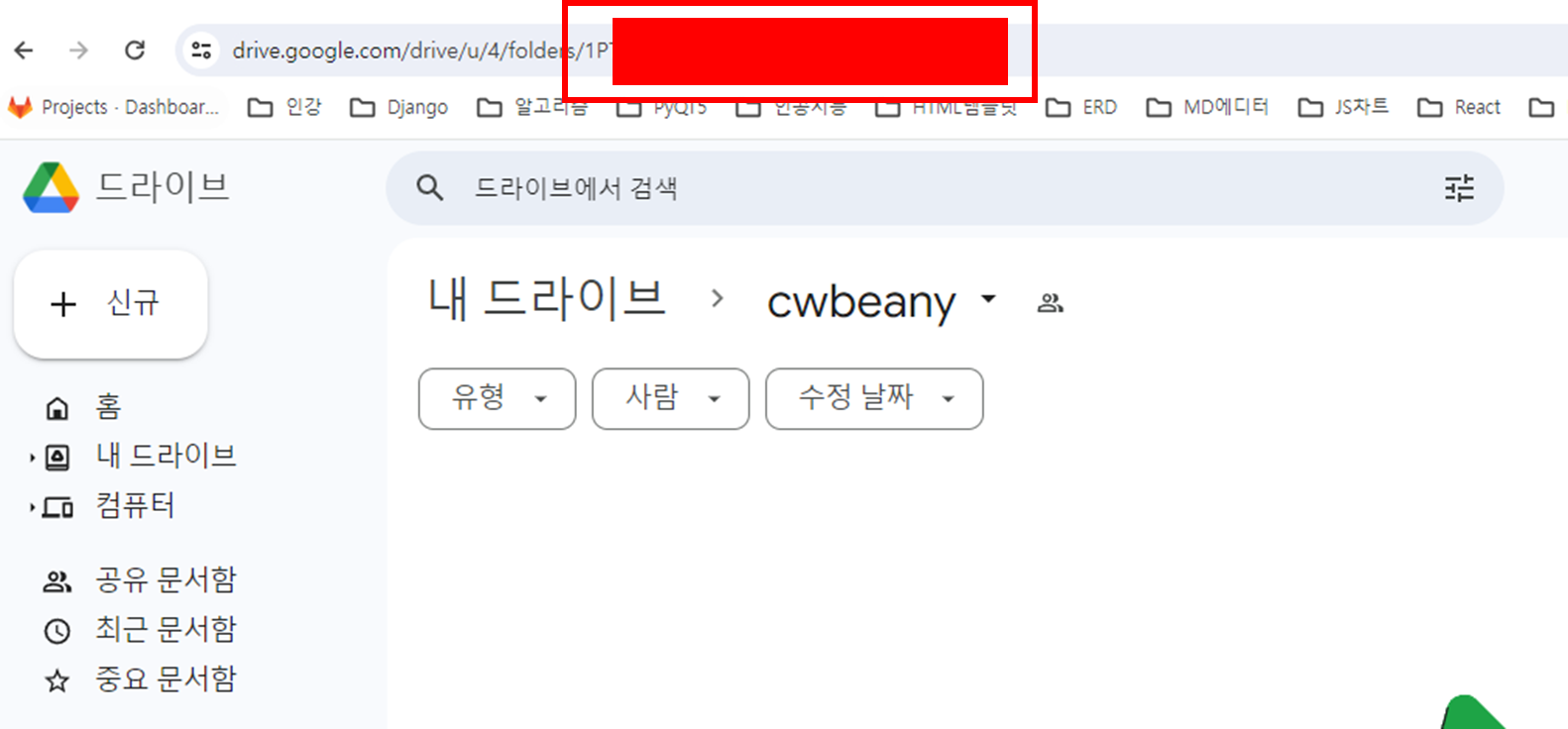
5. 로직 구현을 위한 의존성 라이브러리 설치 및 코드 구현
pip install google-api-python-client google-auth google-auth-oauthlib google-auth-httplib2
google_service_account_file.json 이라는 프로젝트 root 쪽에 만들었습니다.
이 폴더 안에는 사용자 정보 json 내용을 붙여넣습니다.(3. 사용자 인증 정보 설정 부분에 다운로드 받은 파일)
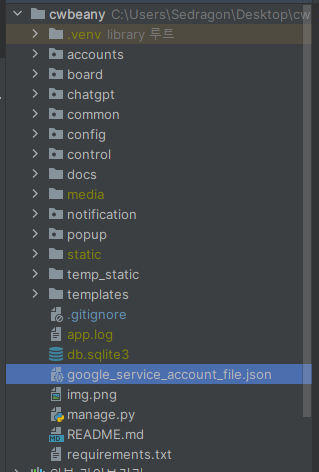
그 후, settings.py 파일에 GOOGLE_SERVICE_ACCOUNT_FILE 와 GOOGLE_API_SCOPES 를 정의합니다.
(settings.py 에 정의하는 건 상수를 정의하는 거라고 생각하시면 됩니다)
GOOGLE_SERVICE_ACCOUNT_FILE = os.path.join(BASE_DIR, 'google_service_account_file.json')
GOOGLE_API_SCOPES = [
'https://www.googleapis.com/auth/drive',
]
기존에 만들었던 google_drive_utils.py 안에 로직을 추가합니다.
from typing import List
from google.oauth2.service_account import Credentials
from googleapiclient.discovery import build
from googleapiclient.http import (
MediaFileUpload,
MediaIoBaseUpload,
)
class GoogleDriveServiceGenerator:
def __init__(self, account_file_path: str, scopes: List[str]):
self.account_file_path = account_file_path
self.scopes = scopes
def generate_service(self):
creds = Credentials.from_service_account_file(
filename=self.account_file_path,
scopes=self.scopes,
)
service = build('drive', 'v3', credentials=creds)
return service
class GoogleDriveService:
def __init__(self, service):
self.service = service
def get_file_list(self, query: str, page_size: int = 1000) -> List[dict]:
results = self.service.files().list(
q=query,
pageSize=page_size,
fields="nextPageToken, files(id, name, mimeType)"
).execute()
items = results.get('files', [])
return items
def upload_file_by_file_path(self, file_name: str, upload_target_file_path: str, upload_drive_folder_target: str) -> str:
file_metadata = {
'name': file_name,
'parents': [upload_drive_folder_target]
}
media = MediaFileUpload(upload_target_file_path, mimetype='application/octet-stream')
file = self.service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return file.get('id')
def upload_file_by_file_obj(self, file_obj, upload_drive_folder_target: str) -> str:
file_metadata = {
'name': file_obj.name,
'parents': [upload_drive_folder_target]
}
media = MediaIoBaseUpload(file_obj, mimetype='application/octet-stream')
file = self.service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return file.get('id')
def delete_file(self, file_id: str):
self.service.files().delete(fileId=file_id).execute()
6. 코드 실행
from common.common_utils.google_utils.google_drive_utils import GoogleDriveService, GoogleDriveServiceGenerator
from django.conf import settings
import os
file_path = os.path.join(settings.BASE_DIR, 'google_service_account_file.json')
google_drive_service = GoogleDriveService(
service=GoogleDriveServiceGenerator(
settings.GOOGLE_SERVICE_ACCOUNT_FILE,
settings.GOOGLE_API_SCOPES,
).generate_service()
)
google_drive_service.upload_file_by_file_path(
file_name='test_aaaaaaa.json',
upload_target_file_path=file_path,
upload_drive_folder_target=settings.GOOGLE_DRIVE_MEDIA_BACKUP_FOLDER_ID,
)
'XXXXXXXEXAMPLEIDXH8V'
성공적으로 업로드 됐습니다~!
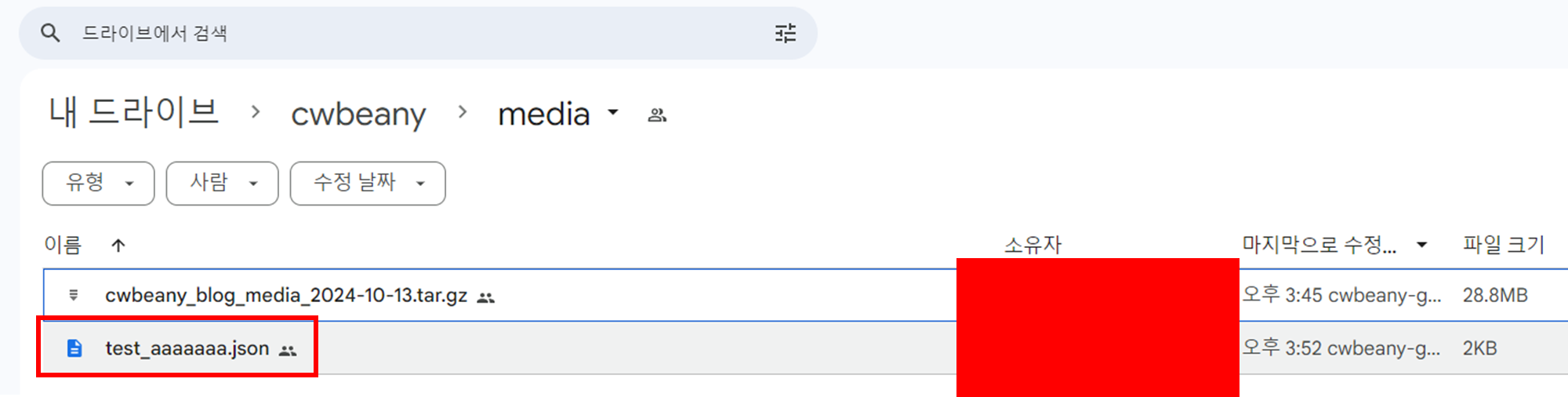
내용을 확인해보니 정상적으로 잘 올라가는 것도 확인했습니다~!
[리팩토링] 8. (2) 메인페이지 좋아요, 댓글 수 Board View 코드 리팩토링
def get_board_set_from_board_group(request, board_group_id):
...완료!!!
def home(request):
...이번장!!!
def board(request, board_url):
...
def post_detail(request, board_url, pk):
...
def reply_write(request, board_url, pk):
...
def rereply_write(request, board_url, pk):
...
def reply_delete(request, board_url, pk):
...
def rereply_delete(request, board_url, pk):
...
def like(request, board_url, pk):
...
get_board_set_from_board_group 리팩토링 정보 보기
Board 앱의 View 함수들을 살펴보니 총 9개의 코드가 존재합니다.
하나하나씩 불필요한 코드를 제거하거나 리팩토링해 보겠습니다
지금은 매번 이 페이지를 조회할 때마다 아래와 같은 코드를 이용해서 좋아요와 댓글 수를 가져오고 있습니다.
def home(request):
...
liked_ordered_post_qs = get_active_posts().select_related(
'board',
'author',
).annotate(
reply_count=Count('replys', distinct=True) + Count('rereply', distinct=True),
like_count=Count('likes', distinct=True),
).order_by(
'-like_count',
'-reply_count',
'-id',
)[:6]
물론 이런 방법으로 데이터를 가져오는 것도 있습니다. 하지만 댓글의 숫자나 좋아요의 숫자가 많아지면 성능이 나빠지는 경향이 있습니다.
지금은 게시글의 좋아요 수와 댓글 수를 각각의 테이블에서 특정 게시글 ID로 조회한 후, 그만큼의 개수를 가져오고 있습니다.
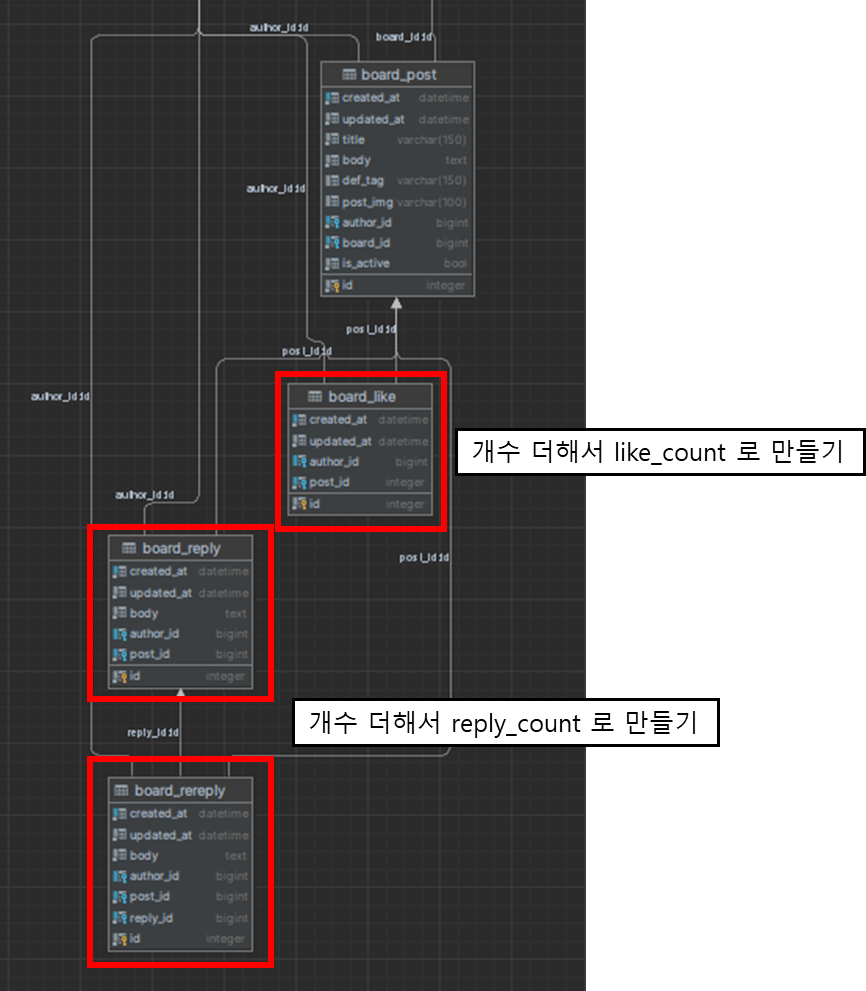
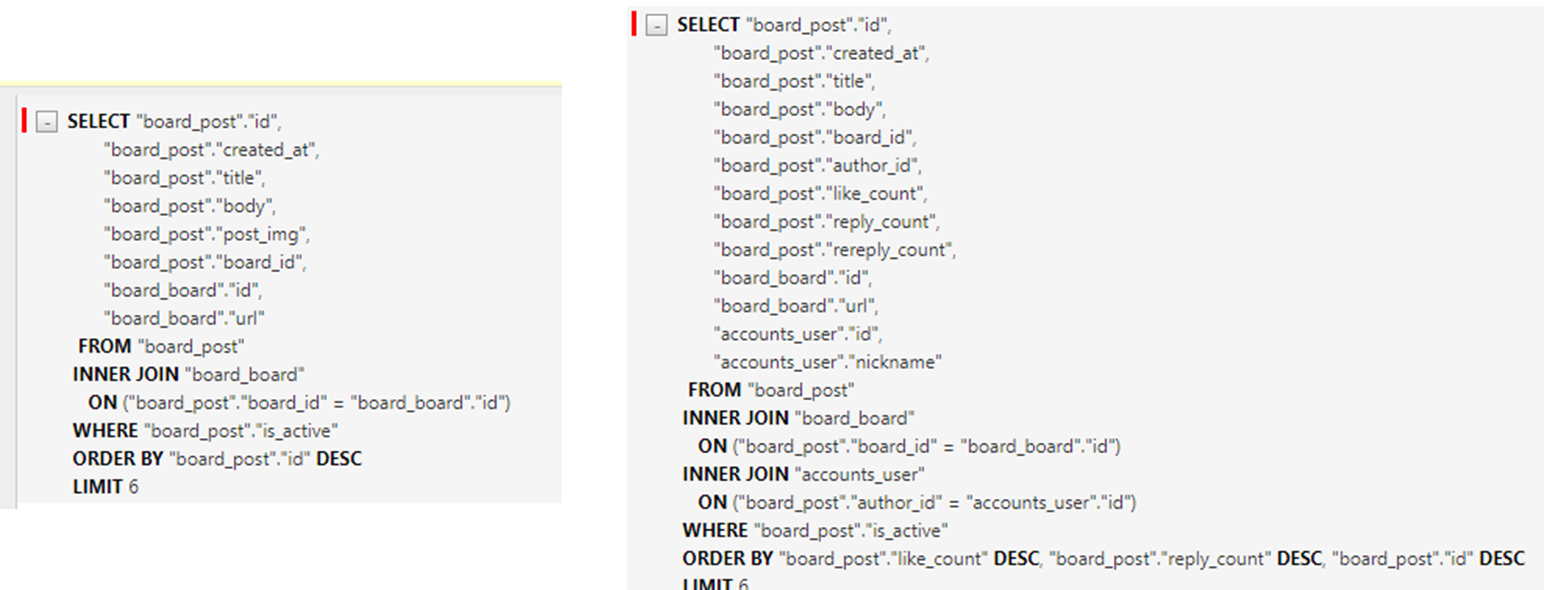
아래 쿼리와 같이 SQL 이 조회가 됩니다.
SELECT "board_post"."id",
...
(COUNT(DISTINCT "board_reply"."id") + COUNT(DISTINCT "board_rereply"."id")) AS "reply_count",
COUNT(DISTINCT "board_like"."id") AS "like_count",
FROM "board_post"
LEFT OUTER JOIN "board_reply"
ON ("board_post"."id" = "board_reply"."post_id")
LEFT OUTER JOIN "board_rereply"
ON ("board_post"."id" = "board_rereply"."post_id")
LEFT OUTER JOIN "board_like"
ON ("board_post"."id" = "board_like"."post_id")
INNER JOIN "board_board"
ON ("board_post"."board_id" = "board_board"."id")
INNER JOIN "accounts_user"
ON ("board_post"."author_id" = "accounts_user"."id")
WHERE "board_post"."is_active"
GROUP BY "board_post"."id",
...
ORDER BY "like_count" DESC, "reply_count" DESC, "board_post"."id" DESC
LIMIT 6
다른 방법이 존재합니다.
방식은 이렇습니다.
- Post 테이블에 추가적인 컬럼 like_count, reply_count, rereply_count를 만듭니다.
- 사용자가 좋아요를 누르거나 좋아요를 취소하는 행동을 하면, Like 테이블에서 Post 기준으로 있는 데이터 개수만큼 조회한 후, like_count를 최신화합니다. (reply_count, rereply_count도 마찬가지입니다.)
- 조회할 때, Count SQL 문을 사용하지 않고, Post에 최신화된 like_count, reply_count, rereply_count 컬럼으로 데이터를 보여줍니다.
로직을 조금 복잡하게 할 것인가, 아니면 성능을 더 좋게 할 것인가?
Trade-off로 따지면, 이번 케이스는 후자가 더 좋다고 판단됩니다.
이제 코드를 작성해 봅시다.
1. 코드 작성
각각의 코드는 아래와 같습니다.
리펙토링은 나중에 신경 쓰고, 이번에 하려는 작업만 신경 씁시다.
(리펙토링은 다른 게시글에...)
@login_required(login_url='/')
def reply_write(request, board_url, pk):
if request.method == 'POST':
post = get_object_or_404(Post, board__url=board_url, pk=pk)
if request.POST.get('reply_body'):
Reply.objects.create(post=post, author=request.user, body=request.POST.get('reply_body'))
return HttpResponseRedirect(reverse('board:post', args=[board_url, pk]))
# 답글 작성
@login_required(login_url='/')
def rereply_write(request, board_url, pk):
reply = get_object_or_404(Reply, id=pk)
if request.method == 'POST' and request.POST.get('rereply'):
rereply = Rereply()
rereply.reply = reply
rereply.author = request.user
rereply.body = request.POST.get('rereply')
rereply.save()
return HttpResponseRedirect(reverse('board:post', args=[board_url, reply.post.id]))
# 댓글 삭제
@login_required(login_url='/')
def reply_delete(request, board_url, pk):
reply = get_object_or_404(Reply, id=pk)
post_id = reply.post.id
if reply.author == request.user or request.user.is_superuser:
reply.delete()
return HttpResponseRedirect(reverse('board:post', args=[board_url, post_id]))
# 답글 삭제
@login_required(login_url='/')
def rereply_delete(request, board_url, pk):
rereply = get_object_or_404(Rereply, id=pk)
post_id = rereply.post.id
if rereply.author == request.user or request.user.is_superuser:
rereply.delete()
return HttpResponseRedirect(reverse('board:post', args=[board_url, post_id]))
# 좋아요 추가 삭제
@login_required(login_url='/')
def like(request, board_url, pk):
post = get_object_or_404(Post, id=pk)
qs = Like.objects.filter(author=request.user, post=post)
if qs.exists():
qs.delete()
else:
Like.objects.create(author=request.user, post=post)
return HttpResponseRedirect(reverse('board:post', args=[board_url, pk]))
먼저 해야하는 작업은 테이블 컬럼 추가합니다.
class Post(TimeStampedModel):
title = models.CharField(max_length=150)
body = RichTextUploadingField()
def_tag = models.CharField(max_length=150, null=True, blank=True)
post_img = models.ImageField(upload_to='post_img/', null=True, blank=True)
board = models.ForeignKey(Board, on_delete=models.CASCADE)
author = models.ForeignKey(settings.AUTH_USER_MODEL, related_name='posts', on_delete=models.CASCADE)
tag_set = models.ManyToManyField('Tag', blank=True)
like_count = models.BigIntegerField(default=0, db_index=True) # 추가
reply_count = models.BigIntegerField(default=0, db_index=True) # 추가
rereply_count = models.BigIntegerField(default=0, db_index=True) # 추가
is_active = models.BooleanField(default=True)
Service Layer 에 좋아요, 댓글, 대댓글 개수를 업데이트하는 함수를 만듭니다.
def update_post_reply_count(post_id: int) -> None:
try:
post = Post.objects.get(id=post_id)
except Post.DoesNotExist:
return
post.reply_count = Reply.objects.filter(post_id=post_id).count()
post.save(update_fields=('reply_count',))
def update_post_rereply_count(post_id: int) -> None:
try:
post = Post.objects.get(id=post_id)
except Post.DoesNotExist:
return
post.rereply_count = Rereply.objects.filter(post_id=post_id).count()
post.save(update_fields=('rereply_count',))
def update_post_like_count(post_id: int) -> None:
try:
post = Post.objects.get(id=post_id)
except Post.DoesNotExist:
return
post.like_count = Like.objects.filter(post_id=post_id).count()
post.save(update_fields=('like_count',))
새로 만든 함수로 View 코드를 수정합니다.
@login_required(login_url='/')
def reply_write(request, board_url, pk):
if request.method == 'POST':
post = get_object_or_404(Post, board__url=board_url, pk=pk)
if request.POST.get('reply_body'):
Reply.objects.create(post=post, author=request.user, body=request.POST.get('reply_body'))
update_post_reply_count(pk) # 여기
return HttpResponseRedirect(reverse('board:post', args=[board_url, pk]))
# 답글 작성
@login_required(login_url='/')
def rereply_write(request, board_url, pk):
reply = get_object_or_404(Reply, id=pk)
if request.method == 'POST' and request.POST.get('rereply'):
rereply = Rereply()
rereply.reply = reply
rereply.author = request.user
rereply.body = request.POST.get('rereply')
rereply.save()
update_post_rereply_count(pk) # 여기
return HttpResponseRedirect(reverse('board:post', args=[board_url, reply.post.id]))
# 댓글 삭제
@login_required(login_url='/')
def reply_delete(request, board_url, pk):
reply = get_object_or_404(Reply, id=pk)
post_id = reply.post.id
if reply.author == request.user or request.user.is_superuser:
reply.delete()
update_post_reply_count(post_id) # 여기
return HttpResponseRedirect(reverse('board:post', args=[board_url, post_id]))
# 답글 삭제
@login_required(login_url='/')
def rereply_delete(request, board_url, pk):
rereply = get_object_or_404(Rereply, id=pk)
post_id = rereply.post.id
if rereply.author == request.user or request.user.is_superuser:
rereply.delete()
update_post_rereply_count(post_id) # 여기
return HttpResponseRedirect(reverse('board:post', args=[board_url, post_id]))
# 좋아요 추가 삭제
@login_required(login_url='/')
def like(request, board_url, pk):
post = get_object_or_404(Post, id=pk)
qs = Like.objects.filter(author=request.user, post=post)
if qs.exists():
qs.delete()
else:
Like.objects.create(author=request.user, post=post)
update_post_like_count(pk) # 여기
return HttpResponseRedirect(reverse('board:post', args=[board_url, pk]))
이제 업데이트하는 로직을 추가했으니, 좋아요와 댓글 수를 조회하는 코드를 업데이트합니다.
def home(request):
...
liked_ordered_post_qs = get_active_posts().select_related(
'board',
'author',
).order_by(
'-like_count',
'-reply_count',
'-id',
).only( # only 이용!
'id',
'board__url',
'author__nickname',
'title',
'body',
'created_at',
'like_count',
'reply_count',
'rereply_count',
)[:6]
...
liked_ordered_posts=[
HomePost(
id=liked_ordered_post.id,
board_url=liked_ordered_post.board.url,
title=liked_ordered_post.title,
body=liked_ordered_post.body,
like_count=liked_ordered_post.like_count,
reply_count=liked_ordered_post.reply_count + liked_ordered_post.rereply_count, # 여기
author_nickname=liked_ordered_post.author.nickname,
created_at=liked_ordered_post.created_at.strftime('%Y-%m-%d'),
)
for liked_ordered_post in liked_ordered_post_qs
],
...
이제 쿼리를 보면 너무 깔끔합니다.
이렇게 한 Controller 안에서 처리하는 방법 말고, Event 방식으로도 업데이트가 가능합니다.
이벤트는 너무 오버스펙이라고 판단하여 사용자가 함수를 호출할 때만 작업하도록 했습니다.
끝~!
생존 신고 겸 사이드프로젝트 서버 구축기
오랜만에 블로그에 글을 쓰는 이유
블로깅은 하지 않았고, 그 기간 무엇을 했냐고 한다면… 일하고, 쉬고, 사이드 프로젝트 하고를 간간히 하면서 보냈다.
그런데 왜 오랜만에 블로그에 글을 썼는지 이야기하자면, 최근 사이드 프로젝트를 실제로 라이브까지 하기 위해 어떤 준비를 했는지 기록하려고 하기 때문이다.
사이드 프로젝트의 주제: "소모품을 관리하는 앱"
사이드 프로젝트의 주제는 "소모품을 관리하는 앱"이다.
아주 많은 사이드 프로젝트 경험으로, 웹으로 만들면 사람들이 주기적으로 이용하지 않는 습성을 파악했다. 그래서 앱으로 만들기로 결심했다.
필자의 스택: 백엔드 개발자, 그런데 프론트도?
우선 필자는 앱 개발에 전무하다.
그~~~~나마 첫 회사에서 선임이 "어~ FE 도 해보실래요?"라고 말했을 때 "넵!! 하겠습니다."라고 반응한 결과, "백엔드 개발자로 취업했지만 프론트엔드까지 안다고?"라는 소설 같은 시츄에이션이 발생해서, React를 대애애애충 쓸 줄 안다. 물론 React를 심도 있게 다루는 수준이 아니라, 그냥 비즈니스가 돌아가게 만드는 정도.

그래서 React 와 비슷한 React Native 를 이용해야겠다고 마음 먹었다.

이 작업을 스스로 하기에는 시간이 너무 많이 걸릴 것 같았고, 요즘 인공지능·AI·제미나이·ChatGPT·클로드 등이 쏟아지면서 "나도 뒤쳐지면 안 되겠다", "그래 어디 어느 정도까지 할 수 있는데?"라는 호기심이 생겼다. 그래서 모든 프론트 작업은 Cursor를 이용해서 하기로 마음먹었다.
(지금까지도 필자는 그저 시킬 뿐, 코드는 전혀 건들지 않는다.)
소모품 관리하는 앱: "소모미" 전에 있었던 프로젝트 - 로드맵(Qosmo)
"소모품 관리하는 앱" 즉, "소모미" 만들기 전에, 할 일들을 만드는 로드맵 같은 프로젝트를 하려고 했었다.
하지만 RN(React Native) 에 전무한 나에게, 노드들이 움직이거나 바꾸거나 하는 UI/UX에서 성능 이슈가 너무 많이 났다.
"아… 인공지능으로는 성능 개선이 필요한 프로젝트는 지금 못하겠구나"라는 교훈을 얻고, 그 사이드 프로젝트는 접었다.
그렇게 시간이 흐르고, 이제 설명하려는 "소모품 관리하는 앱" "소모미" 프로젝트를 하게 됐다.
"소모미"를 하게 된 계기
자취를 하는데, 간혹 냉장고에 계속 방치하는 것들이 꽤 있었다. 언제 샀는지, 지금 냉장고 안에 뭐가 들어 있고, 무엇이 관리되고 있는지 전혀 알 수 없었다. 그래서 이걸 관리하는 앱을 만들어야겠다고 생각해서 시작한 사이드 프로젝트다.
서버 비용에 극도로 민감한 이유
필자는 주기적으로 나가는 사이드 프로젝트 서버 비용에 많이 민감하다.

이유는 단순하다. 내가 먼저 쓰다가 나중에 사람들이 쓸 텐데, 트래픽도 별로 나가지 않는 상태에서 벌써부터 돈이 나가면 수지타산에 맞지 않는다.
아무것도 안 하고 있는데 월 3만 원이 나간다고? 차라리 회사 크루에게 월 3만 원치 커피를 사주겠다….
그래서 어떻게 했는가?
1) Google Cloud 무료 티어 → 막힘
최근에 알게 된 방법 중 하나는 Google Cloud를 이용해서 3개월간 무료로, 새로운 계정을 왔다 갔다 하면서 호스팅하는 것이었다.
이 방법은 한 2025년 중반기까지는 가능했는데, 어느 순간 같은 카드·휴대폰 소유로 Google Cloud가 막아버렸다.
초기에 이 방법으로 2번 정도 "소모미"를 살리면서 작업했다.
(2번이면 대략 6개월 정도. 중간에 바빠서 못 한 경우도 있다.)
이제는 안 되니까 다른 방향을 생각하게 됐다.
2) AWS 프리 티어로 전환
그다음 선택은 AWS 프리 티어였다.
옛날에 필자가 "사이드 프로젝트하면서 돈 나가는 서버 비용"에 가장 처음으로 민감해졌던 플랫폼이 이 AWS였다. 어떤 설정을 했는지 모르겠지만, 서버를 더 이상 사용하지 않고 방치했는데 5만 원이 지갑에서 날아가는 현상이 발생해서, 바로 정이 떨어져 다른 클라우드 서비스를 찾았던 기억이 있다.
어쨌든 다시 보니 AWS 프리 티어가 옛날과는 조금 다르게 정책이 된 것 같아서, 한 번 다시 넘어가게 됐다.
3) "거적대기" 무료보다 실질적인 인프라로
시간이 지나면서, 드디어 나만 쓰는 게 아닌 다른 사람도 쓸 수 있도록 안드로이드 버전을 출시하려고 했다. 그때쯤 "이런 거적대기 같은 무료보다, 실질적으로 쓸 수 있는 걸 해야겠다"는 생각이 들었다.
고민하다가 자주 사용하는 라즈베리파이를 이용하는 것도 생각했는데, Cursor와 채팅하다가 Cursor가 "님~ N100 미니PC 에코비 AMAC 이라는 거 있어요~" 하면서 나를 현혹시켰다.
처음에는 "뭐 그렇군" 했는데, 아~~~~니!!! 외관까지 나를 빠지게 만들었다.

라즈베리파이5와 N100 미니PC 에코비 AMAC을 고민했는데, 가격은 N100이 더 비싸다.
하지만!
- 라즈베리파이5: 발열 때문에 케이스도 사야 하고, 팬 케이스는 소리도 시끄럽고, 초기 설정할 때 모니터도 필요하고… 이런저런 이유로 부담이 컸다.
- N100: 더 이쁘고, 집 데코레이션처럼 쓸 수 있고, 자체 모니터가 달려 있다.
그래서 "비싸더라도 N100이 훨~~~씬 낫겠다"는 생각에 30만 원을 지르고 말았다.
구매를 완료하고, 기존 AWS에 있던 모든 설정을 N100 서버로 옮기고 집에 설치했다.
그런데 모뎀 포트가 "PC1", "PC2", "블로그용 라즈베리파이", "WIFI 공유기"로 다 사용 중이어서, WIFI 공유기로 이 서버는 포트포워딩해서 작업했다.
현재 상태: 테스터 9명, 3명 더 필요
지금은 안드로이드 출시를 위해 비공개 테스터 12명이 있어야 한다. 좁은 인맥을 긁어 긁어 모아서 9명인데, 3명을 더 구해야 하는 상황이다.
AdMob 광고도 달아 놨고, MVP 및 로직 구현도 완료해서 진짜 출시할 만한 수준까지 왔다. 백엔드 설정만으로는 부족해서 모니터링 툴도 넣으려고 했다.
모니터링: APM 대신 SigNoz
APM 툴에는 DataDog, New Relic, Sentry 등이 있지만, 서버 비용 한 푼도 주기적으로 나가는 게 민감한 필자에게는 사치일 뿐이다.

그러다 찾아본 것이 SigNoz라는 오픈소스 모니터링 툴이다. 이걸 적용해서 이제는 모니터링까지 잘 끝내 놓은 상태다.
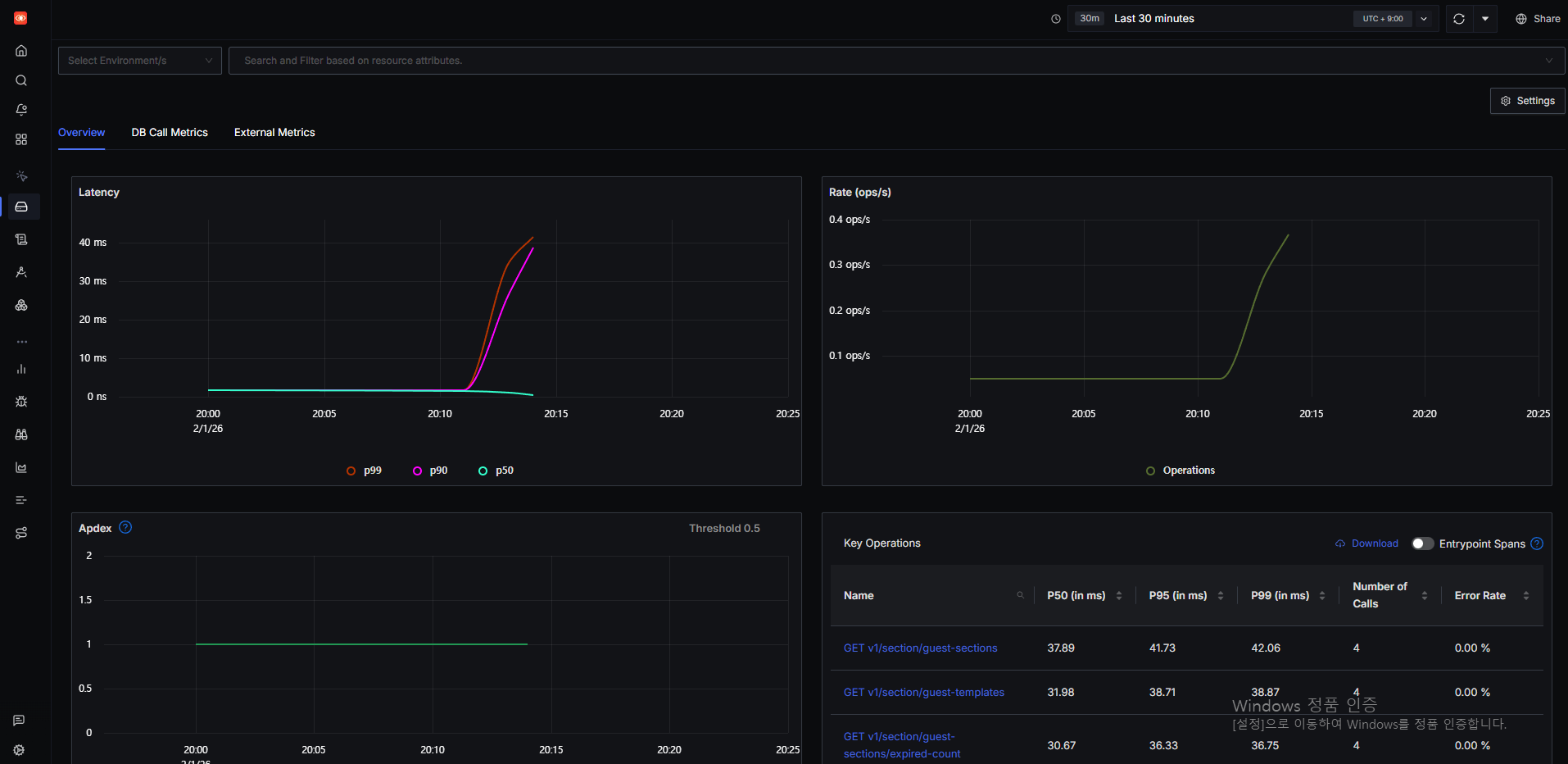
아직 DB, Redis, 서버 자체 메트릭은 수집하지 못하는 것 같지만, 이것도 슬슬 작업하려고 한다.
왜 안드로이드만? iOS는?
"왜 안드로이드만? 아이폰은?"이라고 생각할 수 있다.
- 일단 필자는 안드로이드 유저다.
- iOS는 배포하려면 맥북에서 해야 하고, RN에 대한 지식이 없어서 안드로이드는 어찌저찌 빌드·배포까지 했는데, iOS는 진입 장벽이 더 크다.
- 그래서 일단 안드로이드만 하자~라는 생각에 안드로이드만 작업했다.
iOS도 빨리 하고 싶지만, 시간이 꽤 걸릴 것 같다.
마무리
지금은 이렇게 "소모미"라는 사이드 프로젝트를 하고, 계속 개발해 나가려고 한다.
이 글은 그동안 블로깅을 멈춰 두었던 이유와, "소모미"를 라이브까지 끌어올리기 위해 서버·인프라·모니터링을 어떻게 준비했는지 정리한 기록이다.
[Airflow] Airflow 실습
Airflow 실습
Airflow 설치
Airflow를 실행하기 위해, Airflow 코드를 정의할 폴더를 새로 만듭니다.
mkdir airflow && cd airflow
Airflow는 여러 가지 방법으로 설치할 수 있습니다.
(자세한 내용은 공식 문서를 참고하세요: https://airflow.apache.org/docs/apache-airflow/stable/installation/index.html)
이번 과정에서는 Docker 기반으로 설치할 예정입니다.
우선 docker-compose 파일을 다운로드합니다: https://airflow.apache.org/docs/apache-airflow/3.0.1/docker-compose.yaml
다운로드한 docker-compose.yaml 파일을 앞서 만든 airflow 폴더에 넣습니다.
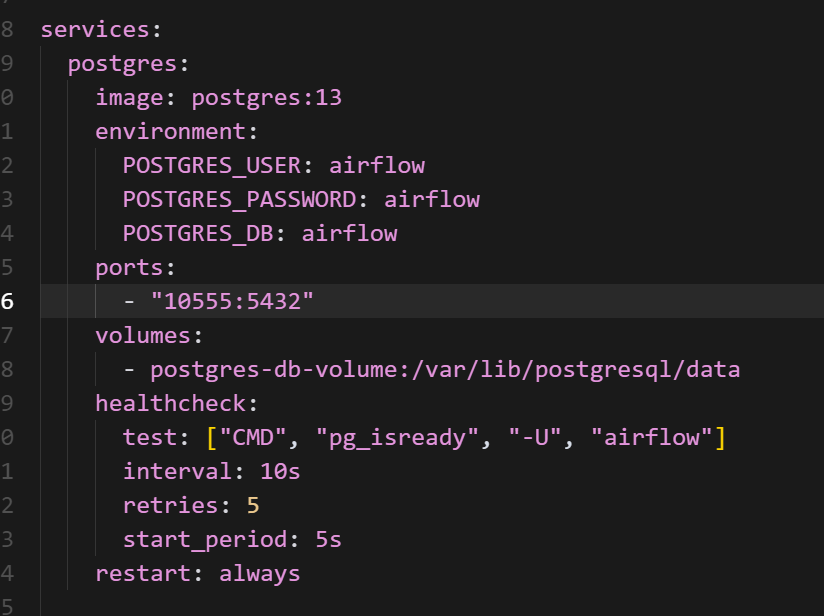
docker-compose 파일 내용을 살펴보면, postgres 항목에 포트 설정이 되어 있지 않습니다.
이 부분은 직접 포트를 지정해 주면 됩니다.
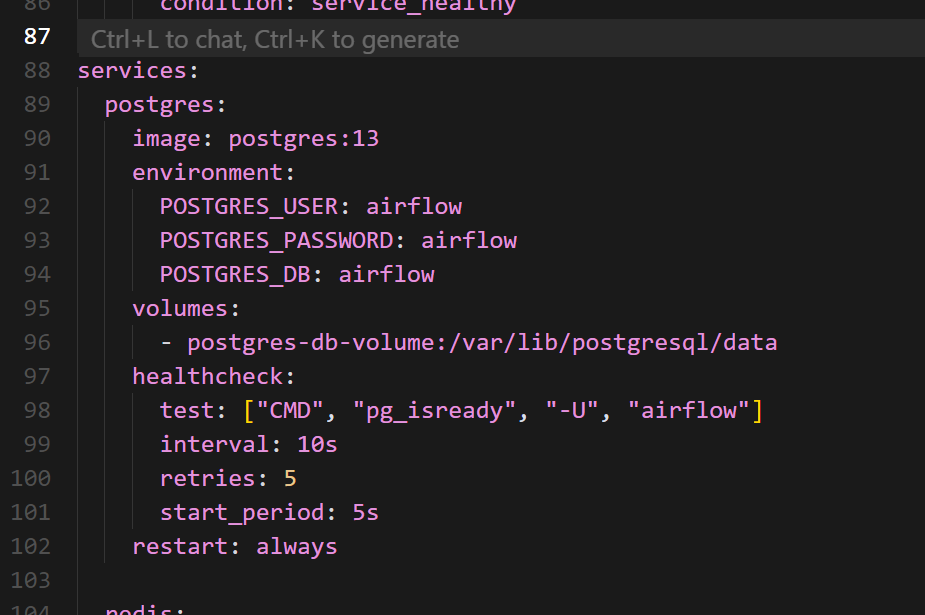
저는 ports 항목을 postgres용으로 따로 지정하지 않은 이유가 있습니다.
제 로컬 컴퓨터에서 이미 postgres 포트를 사용 중이어서, 포트 충돌을 방지하기 위해 해당 설정을 생략했습니다.
만약 로컬에서 postgres 포트를 사용하고 있지 않다면, 컨테이너와 호스트 모두 동일한 포트로 설정해도 무방합니다.
마지막으로, Airflow 실행에 필요한 폴더들을 생성합니다.
airflow 폴더에서 아래 명령어를 실행하면 됩니다:
mkdir -p ./dags ./logs ./plugins ./config
또한 .env 파일을 생성하여 AIRFLOW_UID 값을 정의해주어야 합니다.
아래 명령어를 실행하세요:
echo -e "AIRFLOW_UID=$(id -u)" > .env
이제 Airflow를 실행해봅시다:
docker compose up airflow-init
정상적으로 실행되면 여러 로그가 출력되면서 Airflow가 초기화됩니다.
이제 Airflow 환경이 준비되었습니다!
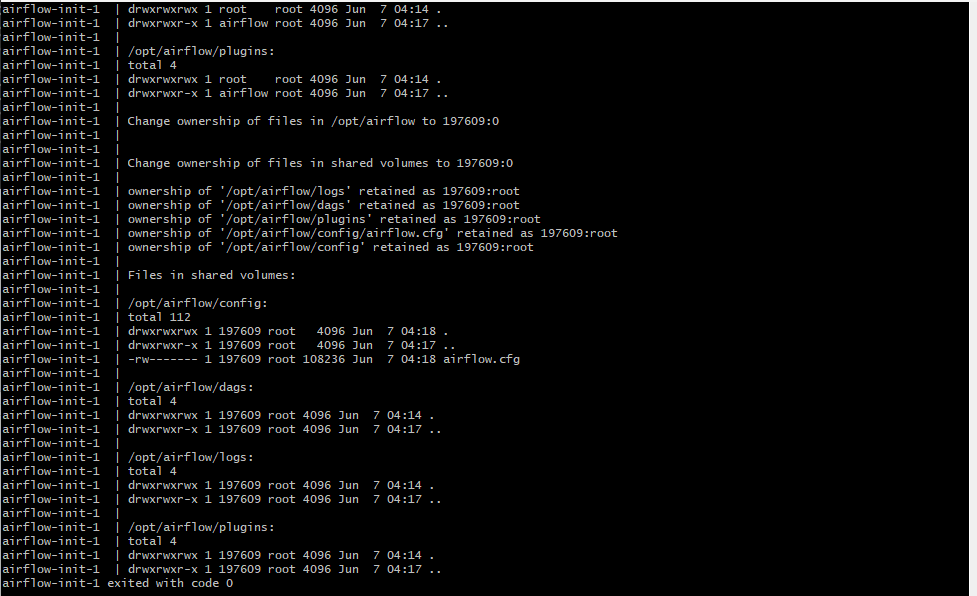
이제 실행해봅시다.
docker compose up
Airflow 접속
여러 초기화 작업이 와다다다 실행됩니다.
준비가 끝나면 아래 주소로 접속해보세요:
브라우저에 접속하면 아래와 같은 Airflow 웹 UI 화면이 나타납니다.
Airflow 웹 UI에 접속하면 로그인 화면이 나타납니다.
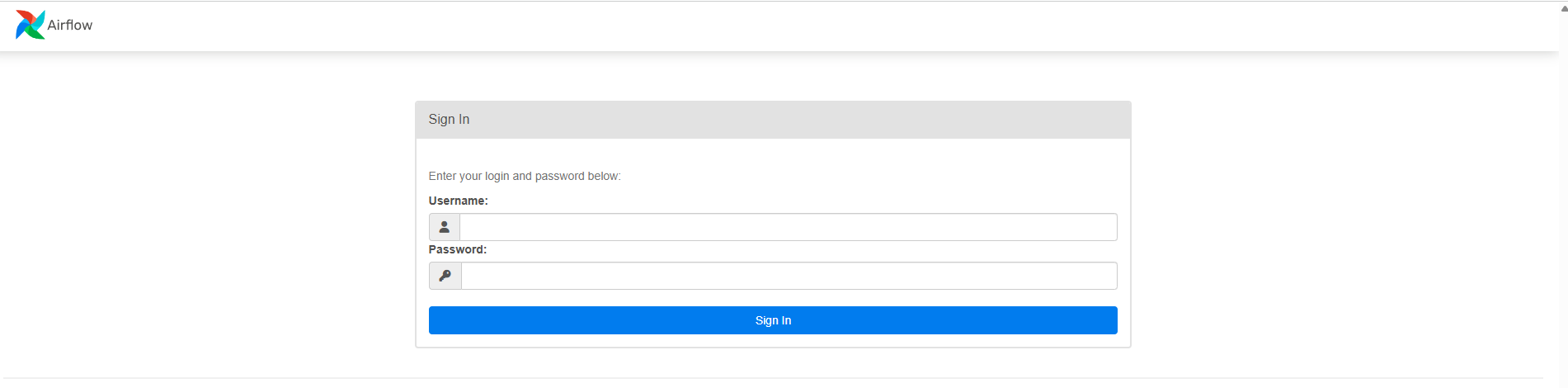
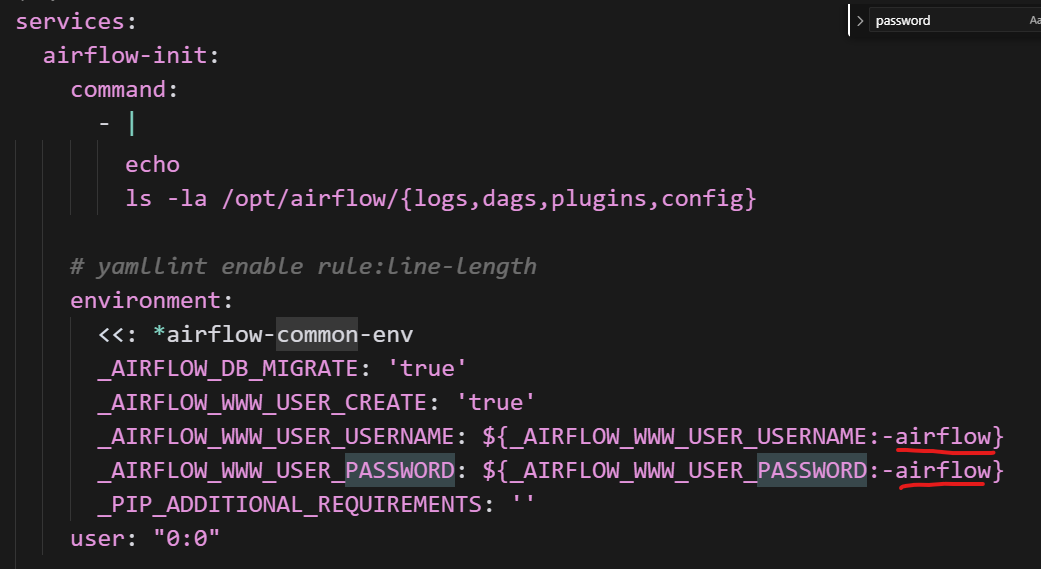
아이디와 비밀번호는 docker-compose.yaml 파일에 미리 정의되어 있습니다.
-
ID:
airflow -
PW:
airflow
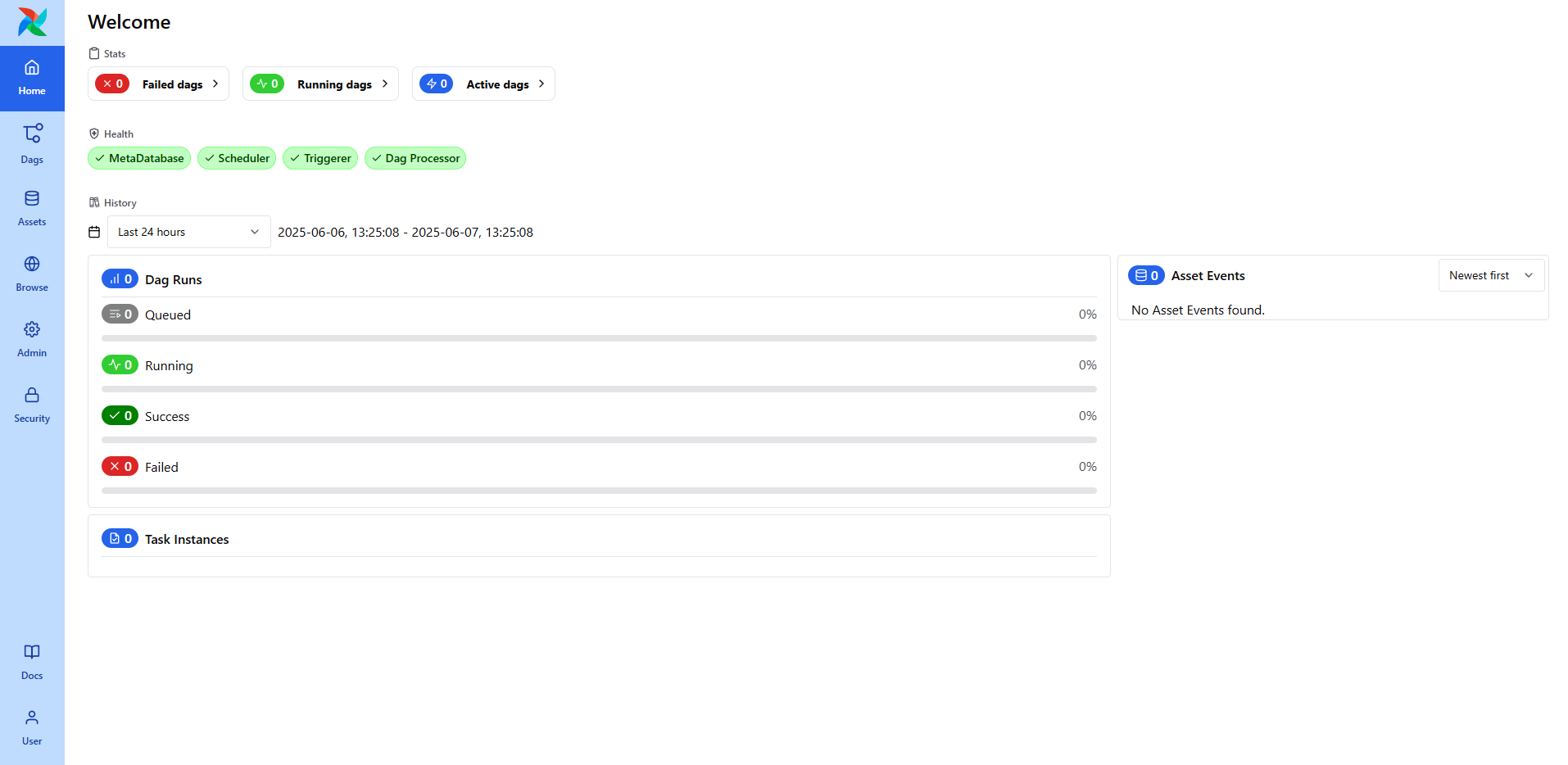
로그인에 성공하면 아래와 같은 Airflow의 웹 UI 화면이 나타납니다.
DAG 목록, 실행 상태, 스케줄 주기 등을 한눈에 확인할 수 있으며,
왼쪽 사이드바를 통해 DAG 생성, 로그 확인, 관리자 설정 등의 기능에 접근할 수 있습니다.
Dags 탭을 클릭한 후 들어가봅시다.
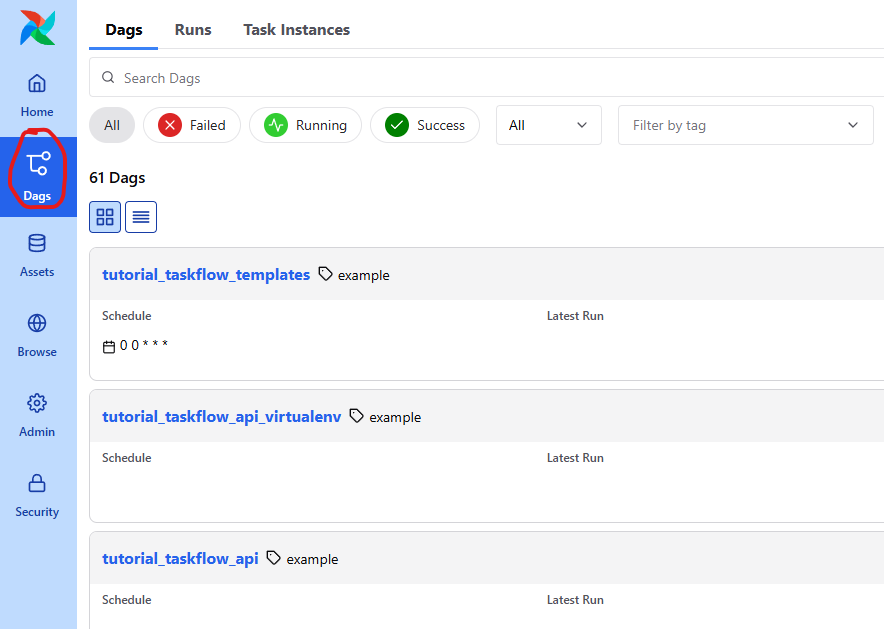
그리고 가독성이 저는 떨어져서 저걸 클릭했습니다.
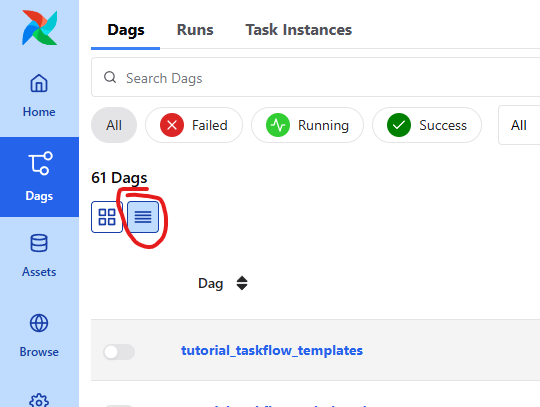
처음 접속하면 아래와 같이 여러 DAG들이 목록에 표시됩니다.
이 DAG들은 모두 Airflow에서 제공하는 예제들입니다
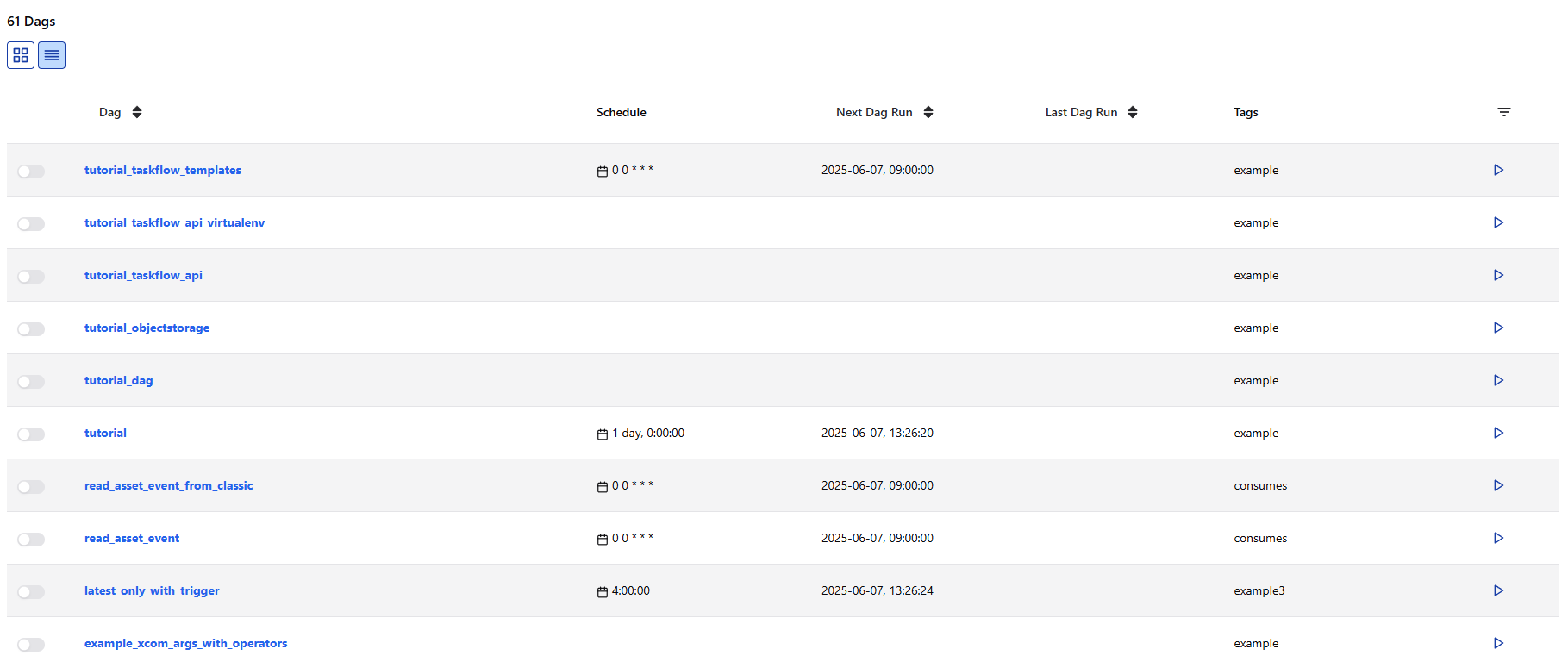
Airflow Dag 정의
예제 DAG들은 나중에 천천히 살펴보기로 하고,
우선 간단하게 현재 날짜를 출력하는 DAG를 하나 만들어보겠습니다.
DAG 정의는 airflow 폴더에 만들었던 dags 폴더 안에 Python 파일로 작성하면 됩니다.
예를 들어, 아래와 같이 python_print.py 파일을 생성해봅시다:
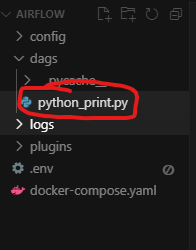
아래 예제와 같이 현재 날짜를 반환하는 코드를 만듭시다.
from __future__ import annotations
from datetime import datetime
# Operators; we need this to operate!
from airflow.providers.standard.operators.python import PythonOperator
# The DAG object; we'll need this to instantiate a DAG
from airflow.sdk import DAG
def print_now():
print(f"지금 시간: {datetime.now()}")
with DAG(
"python_print",
description="A simple tutorial python print DAG",
schedule="* * * * *",
start_date=datetime(2025, 6, 7),
catchup=False,
tags=["python_print"],
) as dag:
print_now = PythonOperator(
task_id="print_now",
python_callable=print_now,
)
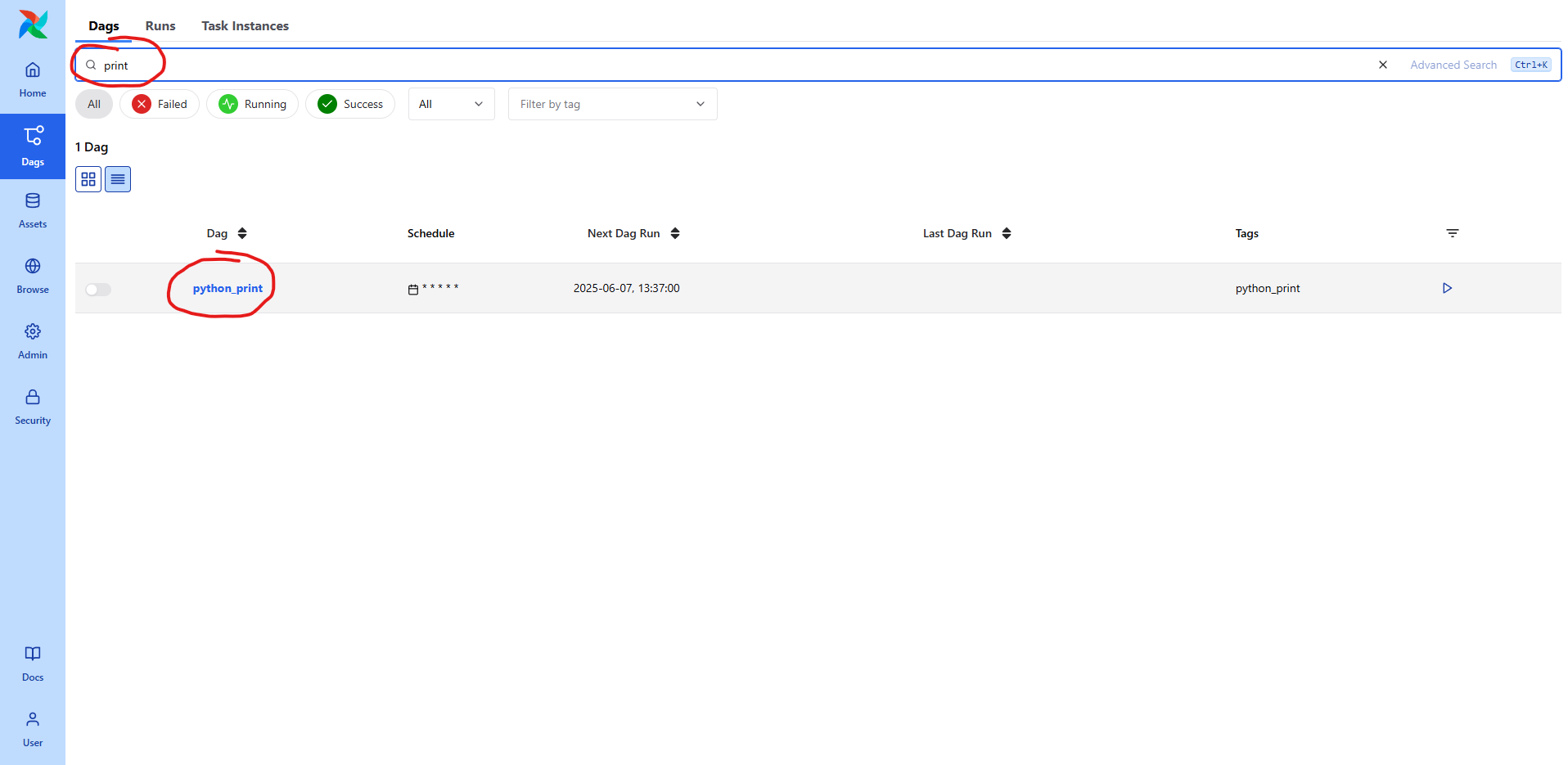
파일 생성 후, 검색으로 찾으면 바로 싱킹돼서 내용이 나옵니다.
스케줄링
스케줄링을 통해 자동 실행되도록 설정해보겠습니다.
기존에는 CRON 표현식을 기준으로 매 분마다 실행되도록 설정했습니다.
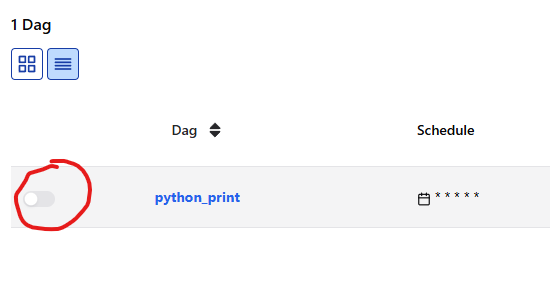
DAG 목록에서 방금 만든 python_print DAG을 클릭해 들어가면,
상단 메뉴에 여러 탭이 있습니다.
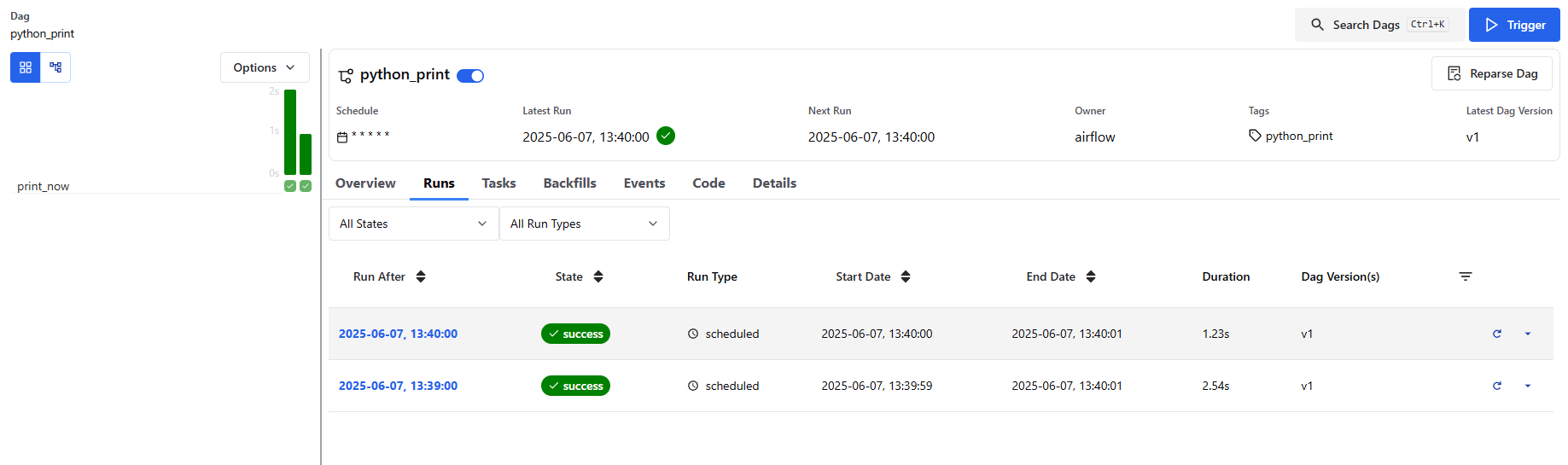
그중에서 Runs 탭을 클릭하면, 지금까지 이 DAG이 실행된 기록을 확인할 수 있습니다.
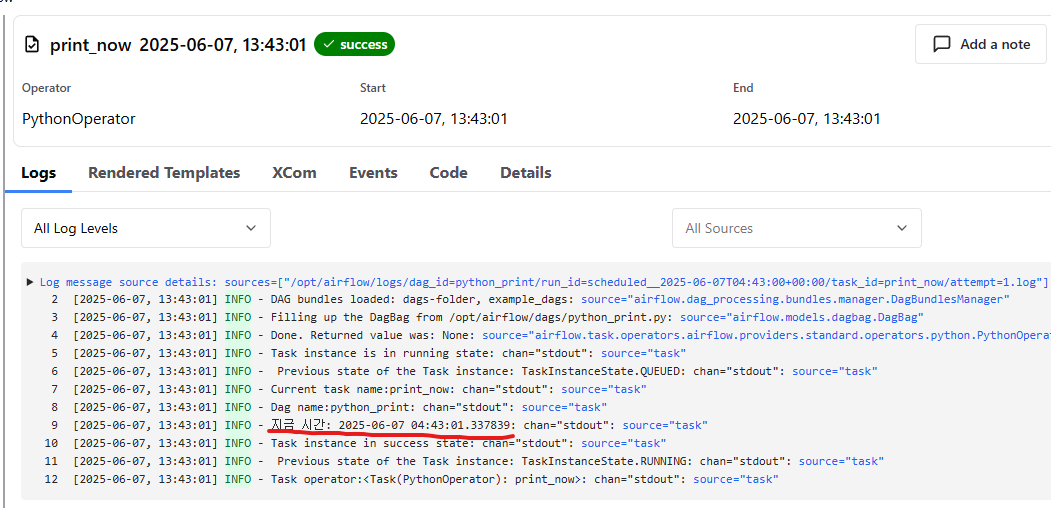
하나를 클릭해서 들어가면 Logs 에서 실행된 결과가 나옵니다.
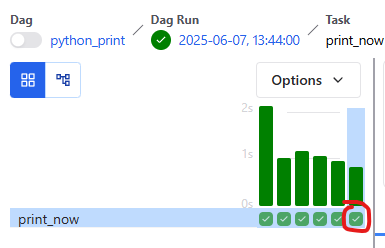
여기 부분을 클릭해도 Log 를 볼 수 있습니다.
트리거
이번에는 스케줄링 방식이 아닌, 직접 실행(Trigger)하는 방식을 사용해보겠습니다.
Airflow 웹 UI에서 실행시키고 싶은 DAG 항목의 오른쪽을 보면,
작은 Trigger 버튼이 있습니다.
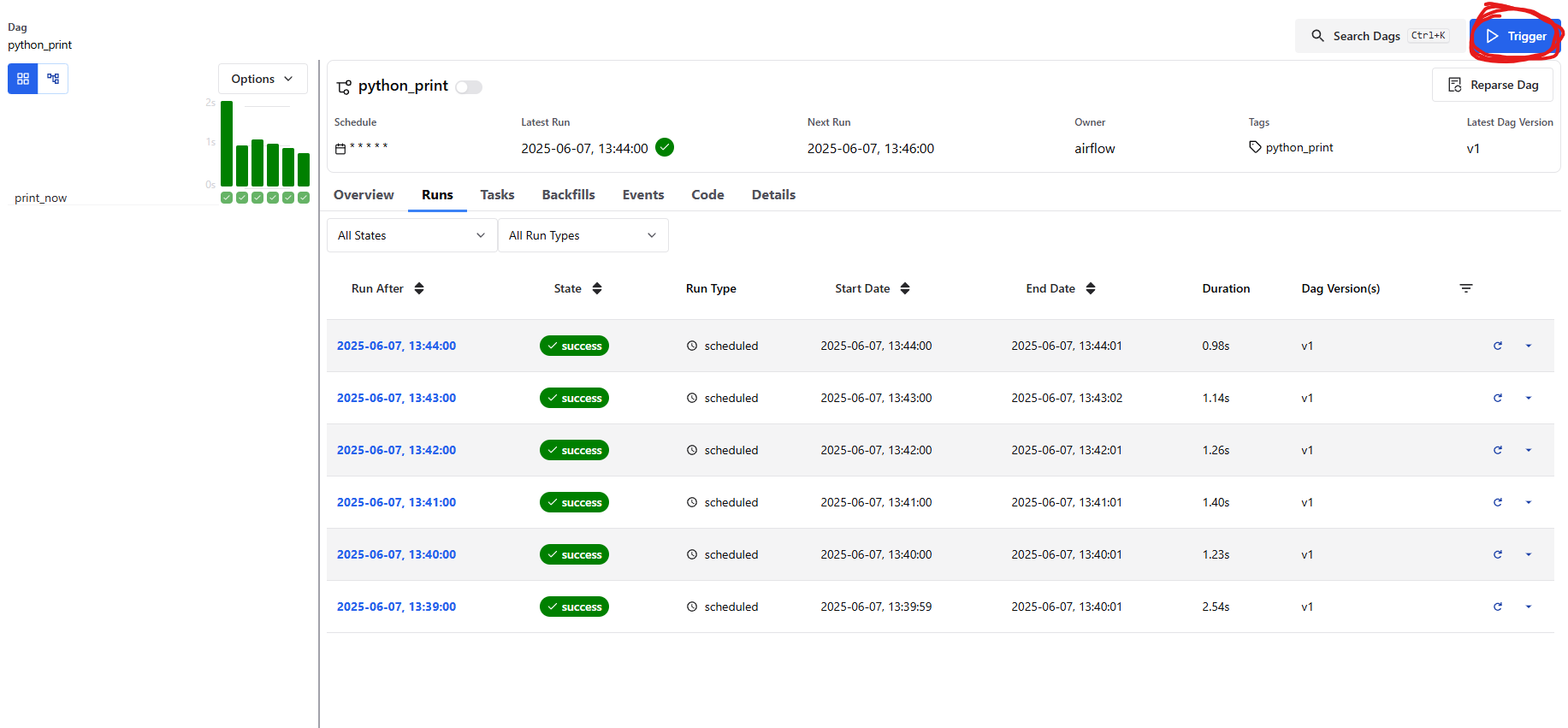
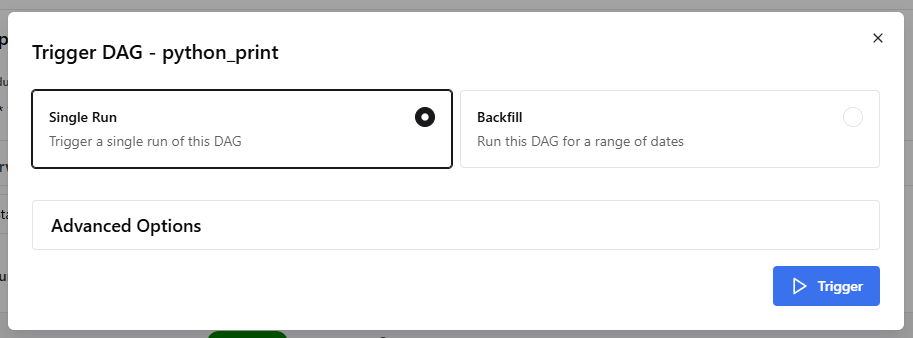
Single Run 을 클릭하고 Trigger 를 클릭하면 실행 됩니다.
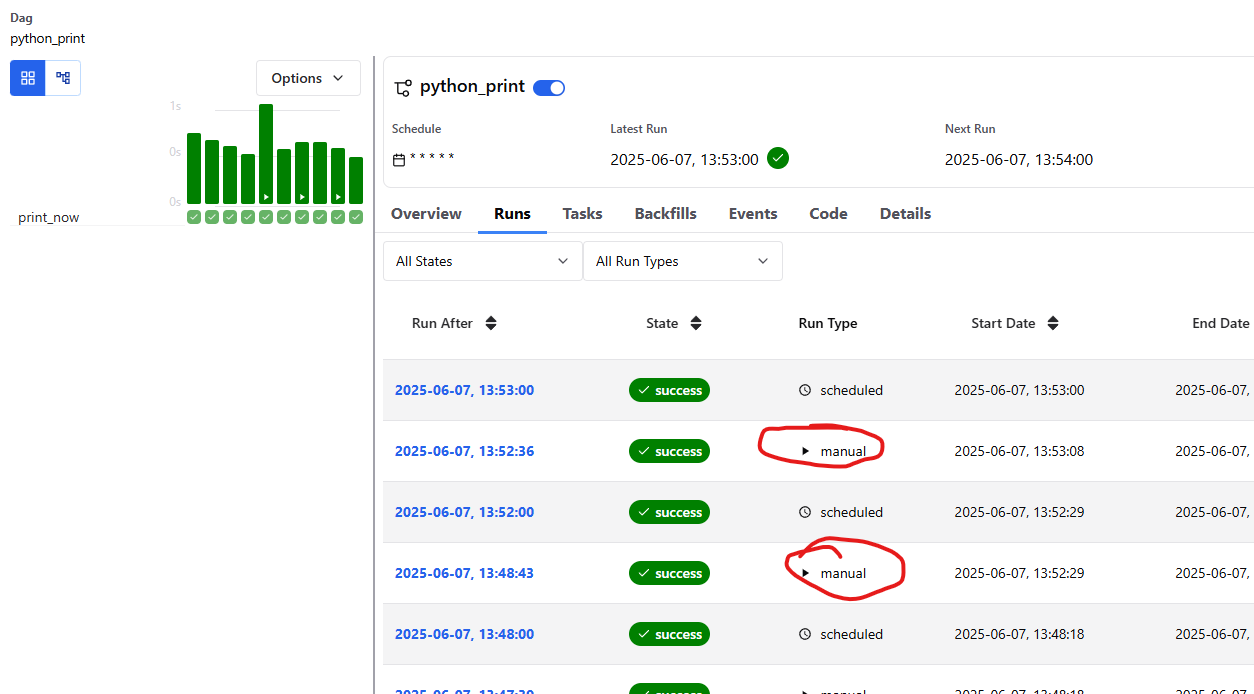
이제 잘 manual 로 실행되는 게 보입니다.
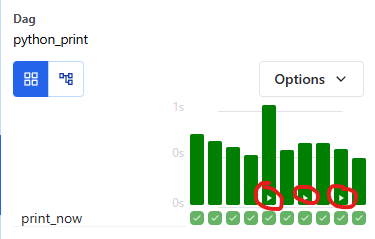
참고로 manual 로 실행되는 것은 아래 이미지와 같이 플레이 표시처럼 보입니다.
참 쉽죠? 더 자세한 내용은 예제 Dag 들을 보고 공부하면 좋을 것 같습니다.
[Airflow] Airflow 에 대해 알아보자
Airflow 정의
https://airflow.apache.org/docs/apache-airflow/stable/index.html
문서를 보면 더 자세히 알 수 있지만 간단하게 제 나름대로 정의하자면
"버튼 딸깍으로 내가 정의한 기능을 수행할 수 있게 도와주는 서비스" + "내가 정의한 기능을 특정 시간에 수행할 수 있게 도와주는 서비스"로 정의할 수 있을 것 같다.
이게 정확하게는 무슨 말인지 이해가 안될 수도 있습니다.
그러면 예제로 무엇을 어떻게 하는지 실질적으로 보면 대애애애충 감이 잡히니 예제 이미지를 보여주면서 설명을 해보겠습니다.
https://cwbeany.com/tip_dev/81#Airflow%20Dag%20%EC%A0%95%EC%9D%98
전체 실습 보기: https://cwbeany.com/tip_dev/81